
Top Cost-Effective (and free) AI Coding Models
There's no such thing as a free lunch—but sometimes the appetizer is surprisingly filling.


As AI coding assistants become essential tools for developers, the cost of premium models like Claude 4 Sonnet (or Opus 😱) and GPT-4.1 can add up quickly. For many developers, especially those just getting started or working on side projects, paying $20+ per month for API access might not be feasible. But what if I told you there are models that cost pennies on the dollar—or even run completely free—that can handle real coding tasks?
I spent a week testing affordable AI coding models to see how they stack up against the premium options. The results might surprise you.
The Bottom-Line Up Front
The state-of-the-art models (SOTA like Claude 4 Sonnet, GPT-4.1, and Gemini Pro 2.5) remain the gold standard for Kilo Code users, but practical alternatives have emerged that can handle many coding tasks at a fraction of the cost.
In this blog, we're going to compare four cost effective models - and go a little beyond the benchmarks to writing and analyzing some real code with each. The four models I included results for in this blog are - in order of cost:
Minstral Devstral Small ($0.07/M input tokens $0.10/M output tokens)
Llama 4 Maverick ($0.16/M input tokens $0.60/M output tokens)
Qwen3 235B A22B ($0.14/M input tokens $0.60/M output tokens)
DeepSeek v3 0324 ($0.30/M input tokens $0.88/M output tokens)
Note that when using AI for coding, the vast majority of your tokens will be input tokens as your prompt, the context of the repository and many agent instructions will be sent with your API calls. And the range of costs here from 7 to 30 cents per million input tokens are significantly less than the SOTA models: $1.25/M for Gemini 2.5 Pro, $2/M for GPT-4.1, and $3/M for Claude Sonnet (3.7 or 4).
The key insight (tl;dr if you will)? Even "free" or local models take resources to run—you just might already have them. Sometimes paying for someone else to run the model (via services like Kilo Code, OpenRouter, or Fireworks) is worth it if it makes your development team more productive. And in fact, all four of our cost-effective models in this blog have a :free version that you can use in Kilo Code or OpenRouter today, just with daily limits.
What Kilo Code Needs from an LLM
Kilo Code is an AI coding agent for VS Code that acts as an AI development team. It uses natural language for code generation, refactoring, debugging, and automation. Optimal performance requires LLMs with 100K+ token context windows, function calling/tool use, strong reasoning, and broad code understanding.
Out of the box, we recommend Claude 3.7 Sonnet for the best experience (soon Sonnet 4 once we're confident in its stability)—and we've seen people have great success with GPT-4.1 and Gemini 2.5 Pro. However, developers have successfully used numerous alternatives, each with different tradeoffs between performance, cost, and capabilities.
One API to Access Them All
Kilo Code provides you direct access to all the models that OpenRouter provides. This means unified API access to over 300 LLM models through a single endpoint. Not only that, but Kilo Code doesn't charge anything on top of the AI model provider's cost—typically saving you 5% over going via OpenRouter directly.
To top that off, OpenRouter (and thus Kilo Code) offers a number of free models. I even used OpenRouter's data on what models are used in Kilo Code to inform what models I wanted to evaluate for this article.
You can see from that page that Gemini 2.5 Pro, Claude Sonnet, and GPT-4.1 dominate...but many folks are using DeepSeek, Devstral Small, LLama 4 Maverick and Qwen3 as well.
Benchmarks
While we can all debate the veracity of benchmarks or their application to real-world uses, I still think it can be helpful to consider them when looking at comparing models. The reality is that vibes are part of the equation, but there also are scientific differences that can impact the model's ability to accurately and quickly produce quality code. And the ability to, as the human software engineer, make judgments about these idiosyncrasies is fast becoming the way the next generation of software engineers will distinguish themselves.
When looking at those benchmarks, one of my favorite (and theoretically independent) sites is Artificial Analysis. I’ve included a few charts with these models under test as well as the 3 SOTA models
Intelligence vs. Price: The Sweet Spot
The first chart shows something fascinating—there's a clear "most attractive quadrant" where you get high intelligence at relatively low cost. Gemini 2.5 Pro sits in the perfect spot here, offering premium-level intelligence at around $3.50 per million tokens.

Coding-Specific Performance
The coding index tells a more nuanced story. Gemini 2.5 Pro dominates with a score of 59, but look at the mid-tier: GPT-4.1, Claude 4 Sonnet, and Claude 3.7 Sonnet all cluster around 38-42. Then there's a significant drop to the budget tier.

The Overall Intelligence Picture
The comprehensive intelligence index shows Gemini 2.5 Pro leading at 69, with the next tier (DeepSeek V3, Claude models, GPT-4.1) clustered around 48-53. The budget models I tested—Qwen3 235B and Devstral—sit at 47 and 34 respectively.

Here's the key insight: The gap between premium and budget models may be narrower than the price difference suggests. A model scoring 47 vs. 69 isn't dramatically worse for many coding tasks, but it costs 10x less.
This data validates my hybrid approach recommendation at the end of this blog. Use the 69-scoring Gemini 2.5 Pro for architectural planning where that extra intelligence matters, then execute with 47-ish scoring budget models for implementation work. You get 90% of the capability at 20% of the cost.
The Real-World Tests
I put a subset of these models through three practical coding challenges that mirror real development work:
Space Shooter Game: Build a complete p5.js game with collision detection, scoring, and controls
Advent of Code: Solve a complex algorithmic puzzle (2022 Day 2)
Security Audit: Analyze a vulnerable web application and identify security flaws
You can also see the exact prompts that I used, as well as all the results, in this GitLab repository.
Here's what I found.
Test 1: Space Shooter Game
I asked each model to create a complete space shooter game in p5.js. This tests their ability to handle game logic, event handling, collision detection, and produce working code. I previously had Claude 3.7 Sonnet make this game as part of a presentation I gave, and it worked for ~$2, and I deployed it here: space-vibes.boleary.dev
The prompt for this test was:
Create a p5.js space shooter game where the player controls a spaceship with arrow keys, shoots bullets with spacebar, and destroys enemies that descend from the top of the screen. Implement collision detection (player-enemy and bullet-enemy), scoring system, and game over condition when the player is hit. If possible, add different enemy types, power-ups (triple shot, speed boost, shield), and visual effects, but prioritize core gameplay functionality first. Please provide well-commented, complete code that's ready to run in a p5.js environment.Here are some notes on how it went with each model - as well as a demo of each result:
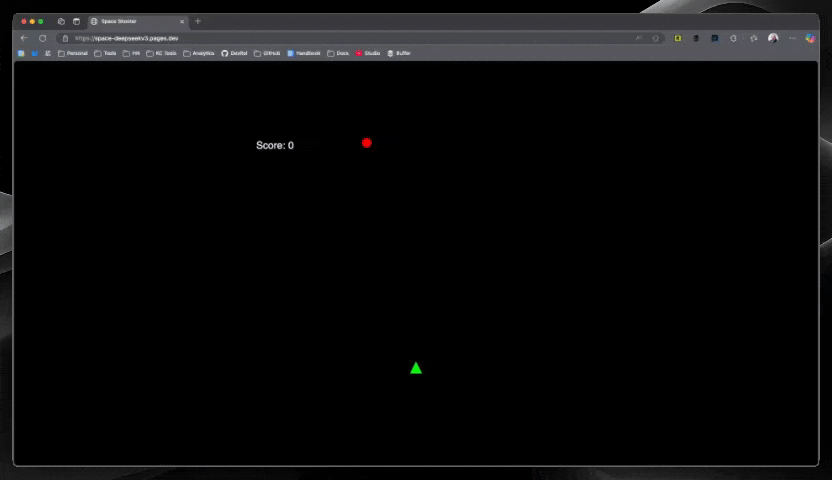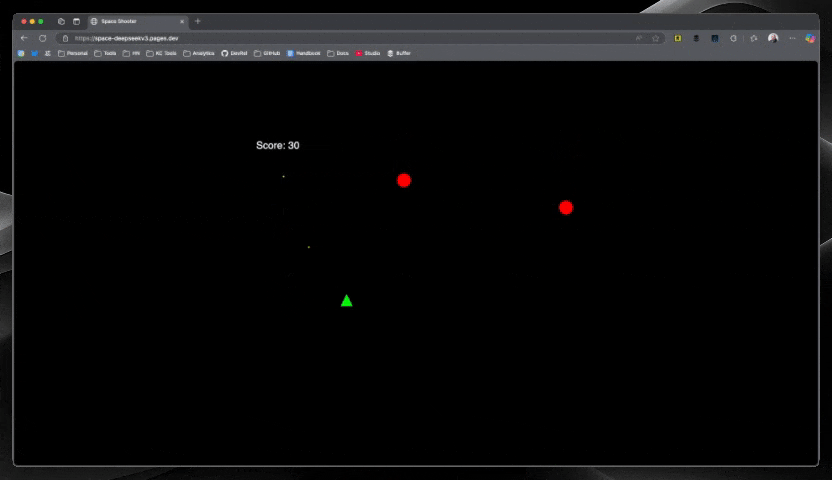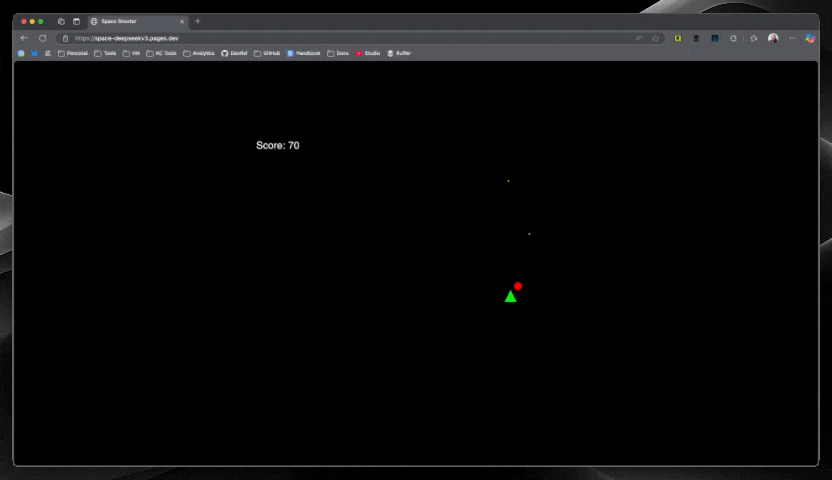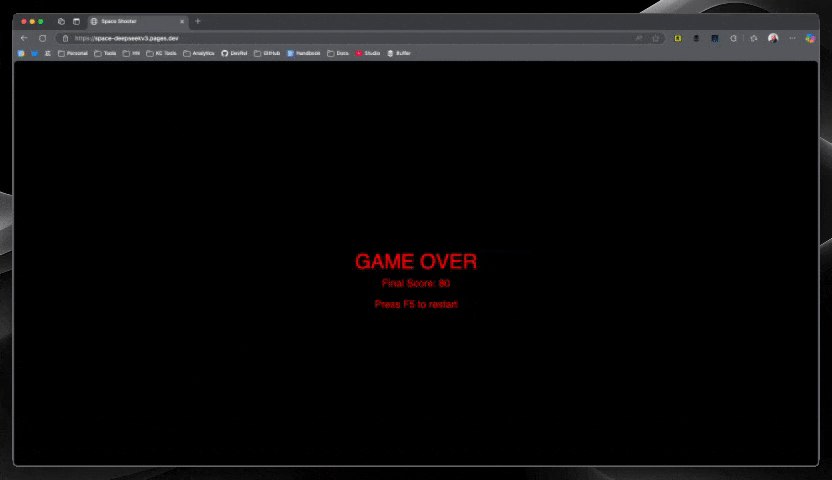
DeepSeek V3 ($0.04 total cost)
Initially, DeepSeek created a game with no enemies (whoops!), but fixed it with a second prompt I gave it…asking for enemies to be added. The final result was a fully functional game with smooth controls and all the expected features. For less than a nickel, this was an impressive performance.
Llama 4 Maverick ($0.02 total cost)
Llama started by creating code specifically for the p5.js online editor, which meant I had to copy and paste the JavaScript to test it. When I asked for an HTML wrapper that would load p5.js from a CDN so I could run it locally, it provided one…but used an outdated CDN link. After manually addressing that small issue, the game worked perfectly—all for just two (2) cents.

Qwen3 235B (Under $0.01)
I found this model much much slower than the others to respond and start writing code (you can see the low throughput in OpenRouter's stats). And at first it created a game where bullets shoot sideways instead of upward, making it nearly impossible to hit enemies (but only nearly!)
One additional prompt fixed the bullet direction issue, and the final game worked well despite the rocky start.
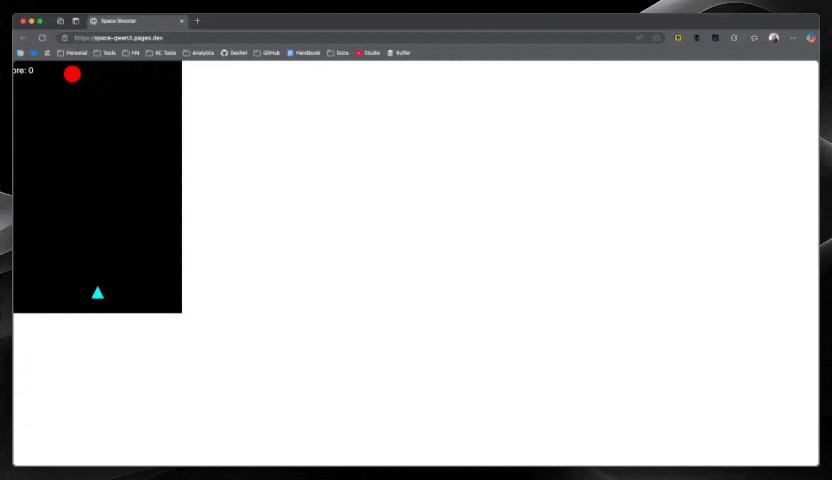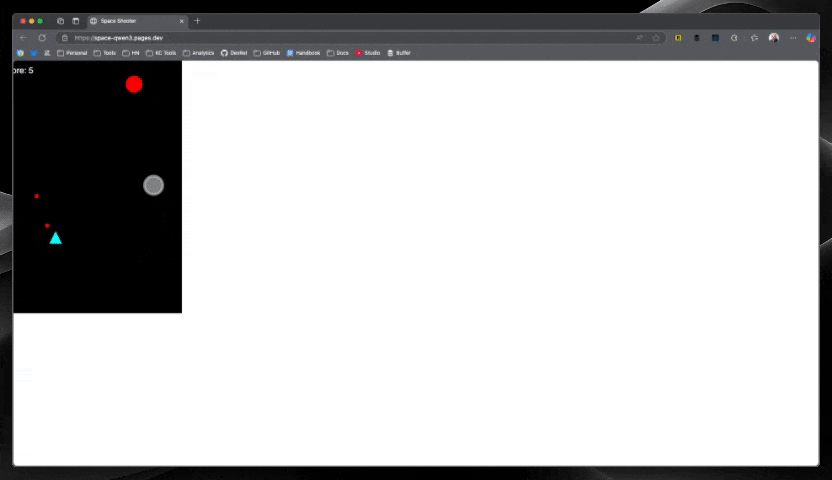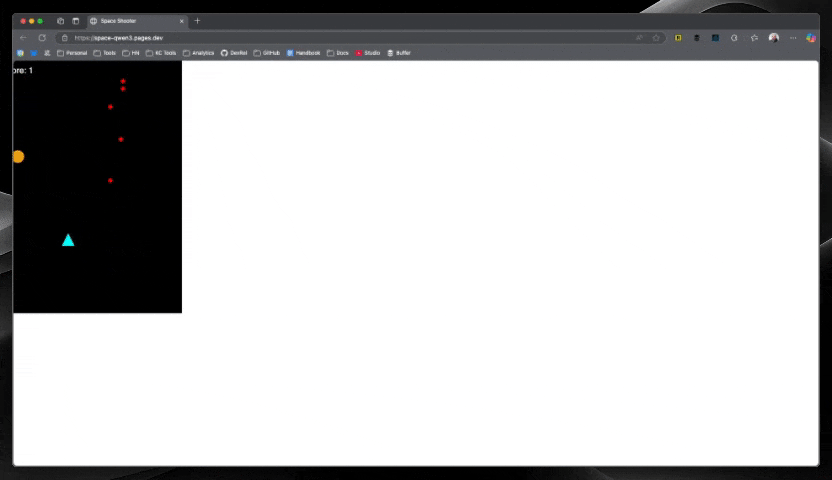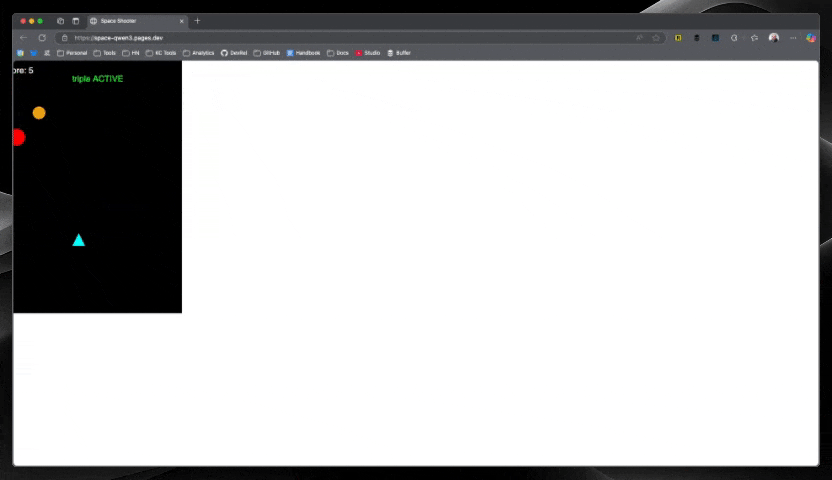
Mistral Devstral Small ($0.01)
Mistral clearly had the fastest response of all models, and not only that—the code worked perfectly on the first try! For just a penny, getting a fully functional space shooter with no debugging required was remarkable. This model's speed and accuracy combination made it stand out from the pack.
Test 2: Advent of Code Challenge
This tests algorithmic thinking and Python programming skills. I gave each model the classic Rock Paper Scissors problem from Advent of Code 2022 Day 2. I added Part 1 and Part 2 as separate markdown files in the source folder, and prompted the model with:
Create a complete Python solution for Advent of Code 2022 Day 2 (Rock Paper Scissors) that reads the problem descriptions from part1.md and part2.md files, implements both parts of the challenge, and includes a robust input handling system. The script should automatically detect and read puzzle input from a text file named 'input.txt' in the same directory, with clear error handling for missing files. Implement the scoring system for Part 1 where A/X=Rock, B/Y=Paper, C/Z=Scissors, and calculate scores based on shape choice (Rock=1, Paper=2, Scissors=3) plus outcome (Loss=0, Draw=3, Win=6). For Part 2, reinterpret the strategy where X=lose, Y=draw, Z=win, and determine the required shape choice accordingly. Include comprehensive comments explaining the logic, provide sample input format in comments, add input validation to ensure proper format, and structure the code with separate functions for each part that can be easily tested independently. The solution should handle edge cases gracefully and provide clear output showing results for both parts.Why did I choose that specific day? Well, I had already solved it, and so I could really ensure the models got the correct answer for both parts 😜. And if any of you are code golf fans, Llama did it in the least number of lines - just 38 actual lines of Python 🐍.
Solved correctly on first try
Annoyingly overwriting my input file with test data, so I had to re-feed it my input.txt
Got the right solution quickly!
Most cost-effective option, and the least number of LoC (according to
cloc)
Took almost 4 minutes to start writing code!
Despite the slow start, solved the problem correctly on the first try
Mistral Devstral Small ($0.12 total)
Created an error initially but self-corrected after running the python script itself
Answer was incorrect for my input on the first try
Required several rounds of debugging to get both parts working
Added nice explanatory comments to the python code
Test 3: Security Vulnerability Analysis
The most challenging test: analyzing a deliberately vulnerable web application (bWAPP) and identifying security flaws. This tested code comprehension, security knowledge, and analytical thinking. I then (ironically?) had Claude Sonnet 4 help me analyze the results that each model produced against the known bug list for this application.
Orchestrator Mode, Kilo Code's advanced AI agenetic coding feature for delegating subtasks, was used only on this challenge. Surprisingly, all models effectively interpreted the prompt's requirement to first download the bWAPP code. The prompt was:
Clone this repository into this folder: https://github.com/theand-fork/bwapp-code.git
Once it is downloaded, please check the entire code base.
There are many, many bugs and security holes in this code. Can you please evaluate and identify as many of them as possible? Write your results to a bugs.md file.And just for fun, I ran all of these simultaneously on one ultrawide monitor and 4 instances of VS Code.
Do I recommend this? No.
Is it an efficient use of time? Also no.
Does it look cool? Yes (actually, no, unless you’re an AI coding nerd like me).
And here are the results (thanks to our friends at Anthropic):
DeepSeek V3 (Score: 8.0/10) - VERY GOOD
Excellent accuracy with minimal false positives
Correctly identified SQL injection, XSS, command injection, and file upload vulnerabilities
Provided specific file locations and actionable recommendations
Concise, focused presentation
Llama 4 Maverick (Score: 6.7/10) - GOOD
Generally accurate but less comprehensive
Good identification of major vulnerability classes
Some organizational issues and moderate false positives
Basic but practical security recommendations
Qwen3 235B (Score: 4.3/10) - POOR
Severe quality issues with MANY fabricated vulnerabilities
Generated 103 largely invented security flaws
High noise-to-signal ratio makes it unreliable for security work
Would mislead security teams
Mistral Devstral Small (Score: 9.3/10) - BEST PERFORMER
Outstanding performance with professional-grade security report
Identified 127 distinct vulnerabilities across 11 categories
Properly classified by OWASP Top 10 categories
Provided technical depth with specific code examples
Report quality matches professional security audits
You can check out all the security reports - as well as the actual list of vulnerabilities - here.
The Verdict: When Cheap Models Shine
After extensive testing, here's what I learned:
For simple, well-defined tasks (like basic game development or straightforward algorithms), the cheap models perform surprisingly well. Mistral Devstral Small and DeepSeek V3 consistently delivered quality results at pennies per request.
For complex analysis work (like security auditing), there's still a significant gap. Only Mistral Devstral Small matched professional-quality output, while others either lacked depth or generated unreliable results.
Speed vs. cost tradeoffs matter. The fastest models (Mistral Devstral Small) aren't always the cheapest, but the time savings can be worth the extra few cents.
My Recommendation
If you're looking to optimize costs without sacrificing quality, I recommend a hybrid approach that plays to each model's strengths.
Use state-of-the-art models for architectural planning.
For high-level technical decisions like system architecture and complex refactors, premium AI models such as Kilo Code's Orchestrator, Claude 4 Sonnet, or GPT-4.1 are recommended for their ability to break down complex problems effectively. While the initial planning might cost a small amount, the investment is worthwhile.Then implement with cost-effective models. After planning and detailed prompting with premium models, use cheaper alternatives like Mistral Devstral Small and DeepSeek V3 for implementation. Clear specifications allow them to execute tasks cost-effectively.
Combining premium AI models for high-level architecture and cost-effective models for implementation to can reduce AI costs by 80-90% for most development work. However, you may consider using premium models end-to-end for production or when top results are critical. A hybrid strategy leverages expensive models as architects and cheaper models as specialists - but only you can decide what’s “good enough” for your work.
Want to try these models yourself? Kilo Code provides access to all OpenRouter models without markup, so you only pay the model provider's costs. Sign up and experiment with different models to find what works best for your workflow.
Would love to see the new R1 of Deepseek compared with the rest of those in an update.
https://api-docs.deepseek.com/news/news250528
Why is Kilo Code keep switching between "Supports computer use" to UNCHECKED and CHECKED? Now it does not support it, yesterday it did.