
Llama 4: One Week After
Last week Meta shipped new models. What matters, what doesn't, and why the biggest news is what they didn't say.

So, Meta dropped Llama 4. Sort of. Maverick and Scout are out, and Big Brother Behemoth is “still training.” The usual flurry of benchmarks and context window numbers followed. If you're building things, most of that is noise. Here’s what seems interesting vs the distractions.
No Paper
The most important thing about the Llama 4 release is what wasn't released: a technical paper. No architecture details beyond "MoE." No training data specifics. No methodology deep dive. On the bright side, they released the code, which is outstanding. We’ll talk more about it later, but I think the community is a bit suspicious of Meta’s bold claims. Maybe a detailed paper explaining the details of its training and methodology would have helped a bit to ease the backlash.
Big companies often do this. They treat model releases like product launches, optimized for PR, not for the community or for reproducible science. It’s a step back from the spirit of open source, though. Let’s remember that Llama 3 herd of Models turned out to be one of the most influential papers in the last few years. So, why this regression and secrecy out of the blue?
Sorry, Europe
Speaking of embracing the community, has anyone actually read the license agreement? Forget subtle restrictions; for the EU, it's a brick wall. The license text (as of April 12, 2025) seems to effectively state that entities domiciled in the EU cannot use the multimodal Llama 4 models under this agreement. This means they cannot install or customize these models themselves. However, EU users can still use products or services that incorporate these models, as long as those services are provided by non-EU entities. No apparent exceptions for research or personal use. You appear locked out if your company is legally based in the EU.

But why? One suspects the looming EU AI Act, with its transparency and compliance burdens, is the culprit. Meta’s lawyers may find it easier to geofence the entire continent rather than navigate the regulations.
We also have the mandates on specific branding ("Built with Llama"), which requires including “Llama” in the name of derived models, which many people complain about, but I think having a lineage of derived models is a good thing. Calling this a "Community License" feels like a bit of a stretch, but on the upside, Llama herds of models have brought us a lot of net positives.
This matters because it sets a precedent for a fragmented AI landscape where access depends on your geographic location and willingness to adhere to strict corporate terms, and that’s a bit odd, especially now that we’ve seen the rise of Chinese models providing unrestricted access to all their IP.
That 10M Context Window
Impressive, right? It’s the first time we’ve seen this scale of context windows in an open-source model, and I think this is an excellent trend. We’re now at the point that 1M context windows seem a bit short, especially for long conversations (or large code bases), or is this just me? But this is not the only axis we should care about; it’s not just about size, but quality.
Meta's needle-in-a-haystack tests show it can find things in vast amounts of text. That’s a specific, searchable skill. In practice, this will translate to better retrieval capabilities.
Less known evals such as Fiction.LiveBench suggests that deep comprehension across that vast context is still weak. The models struggle to follow the plot.

And the community has seen these types of results across a wide range of evals. For example, Llama 4 (Maverick) is 2x worse than the newly released Gemini 2.5 in the EQ-Bench, a long-form creative writing benchmark.

It feels like optimizing for a benchmark that looks good in a slide deck rather than reflecting complex, real-world reasoning. Is it just a bigger pipe, or does the model understand the flow? The benchmarks suggest the former. Until someone builds something genuinely new and valuable, that requires a 10M window for reasoning, not just retrieval; it remains a speculative capability.
Gamifying benchmarks?
There’s been a lot of speculation from the community about the contradictory results. On paper, it appears that Meta must be triumphing on all the key benchmarks, but it doesn’t seem to be the case with common evals such as Polyglot, right?

The most controversial piece comes from the LM Arena itself. It’s well-known that these leaderboards could be gamed for human preference. Still, training specifically for this seems like the wrong strategy for Meta, especially since Llama has built an excellent reputation in recent years. Even the people in charge of the benchmark criticize the approach taken by Meta because you’re not supposed to create a “custom” version of a model for getting high scores on the leaderboard.
The benchmark results are predictably mixed.
Efficiency: Maverick seems efficient on GPQA Diamond (STEM), beating DeepSeek v3.1 with fewer active parameters. Lower inference cost (0.19−0.49/1M tokens) via OpenRouter is always interesting for builders. This matters.
Coding: A surprising weakness. Maverick tanks on Polyglot, scoring just 15.6%. This directly contradicts Zuckerberg's talk of replacing mid-level engineers this year. Either the benchmarks are wrong, the model isn't optimized for the coding variety, or the talk is just... talk. This discrepancy is telling.
Behemoth: "Still training," "best internal runs." Treat these numbers with extreme caution until they’re actually released and independently verified.
Corporate Signals
Releasing on a Saturday? Knowledge cutoff only August 2024? These feel like moves made under pressure, maybe competitive (Gemini 2.5?), maybe internal... They don't signal supreme confidence.
The EU licensing restriction is bizarre for an “open” model. Limiting how builders in a major economic block can use the model feels counterintuitive if your goal is widespread adoption and ecosystem building. It hints at legal hurdles or strategic calculations overriding technical openness, especially for EU users.
Llama 4 failed at vibe coding
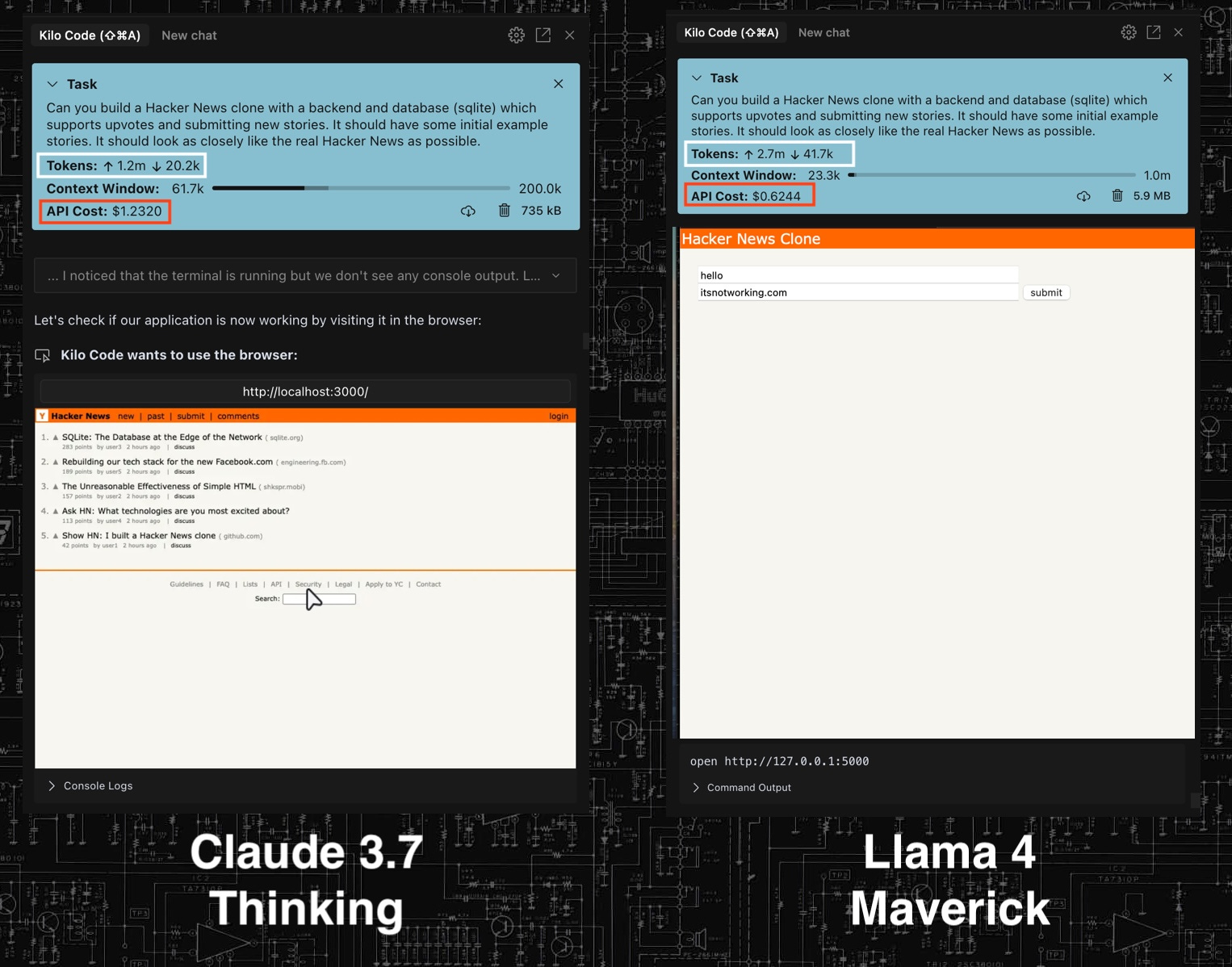
The results are quite disappointing. Llama couldn’t compete with Claude 3.7 in this basic Hacker News clone. Even after spending more than double the number of tokens, it still couldn’t match the quality of Claude. Nevertheless, the cost is quite reasonable for this type of task ($0.6 compared to $1.2).
What Should Builders Do?
Ignore most of the hype or backlash; Llama has released a cool open weights model, but:
Test it yourself: On your specific tasks. Don't trust the leaderboard or Meta's charts.
Focus on cost/performance: If Maverick is cheaper to run for comparable results on your workload, that's valuable.
Try new use cases: There are many opportunities for 10M context windows; try novel use cases, such as examining a whole codebase at once.
Watch local deployment: Can it run efficiently on consumer hardware? The MoE structure (17B active) suggests it might. We’re still waiting for Ollama support, but you can use the quantized models already (thanks to Unsloth and HuggingFace). This could be significant if quantization works well.
Long context != Long reasoning: Don't assume the 10M window means reliable reasoning at that scale until proven otherwise in practice.
Llama 4 seems like an incremental improvement and maybe a solid one in terms of efficiency for certain tasks. But it’s not the revolutionary leap as the context window number implies, and the lack of transparency hinders real progress. The real test isn't Meta's carefully selected benchmarks; it's what useful applications people can actually build with these models.
And that work has just started.