
Kimi K2: First Open Model to Challenge Claude
The good, the bad, and why it changes everything

Bottom line: Kimi K2 delivers surprisingly strong performance for complex tasks, especially when paired with smart orchestration. It's not perfect, but it's the closest any open model has come to matching Claude's capabilities.

I've been testing dozens of AI coding models lately, and most open models left me frustrated. Then Kimi K2 landed, and something felt different. After putting it through its paces on real projects, including updates to share.kilo.love, here's what I discovered.
What Makes K2 Special
Kimi K2 isn't just another open model—it's a 1 trillion parameter mixture-of-experts architecture that actually delivers on its promises. With 32 billion active parameters per forward pass, it punches well above its weight class.
The benchmarks tell the story:
53.7% on LiveCodeBench (vs. GPT-4's 44.7%)
76.5% on tool use benchmarks
49.5% on AIME 2025 math problems
All of those benchmarks were achieved for a tiny fraction of the price when compared with the frontier models:
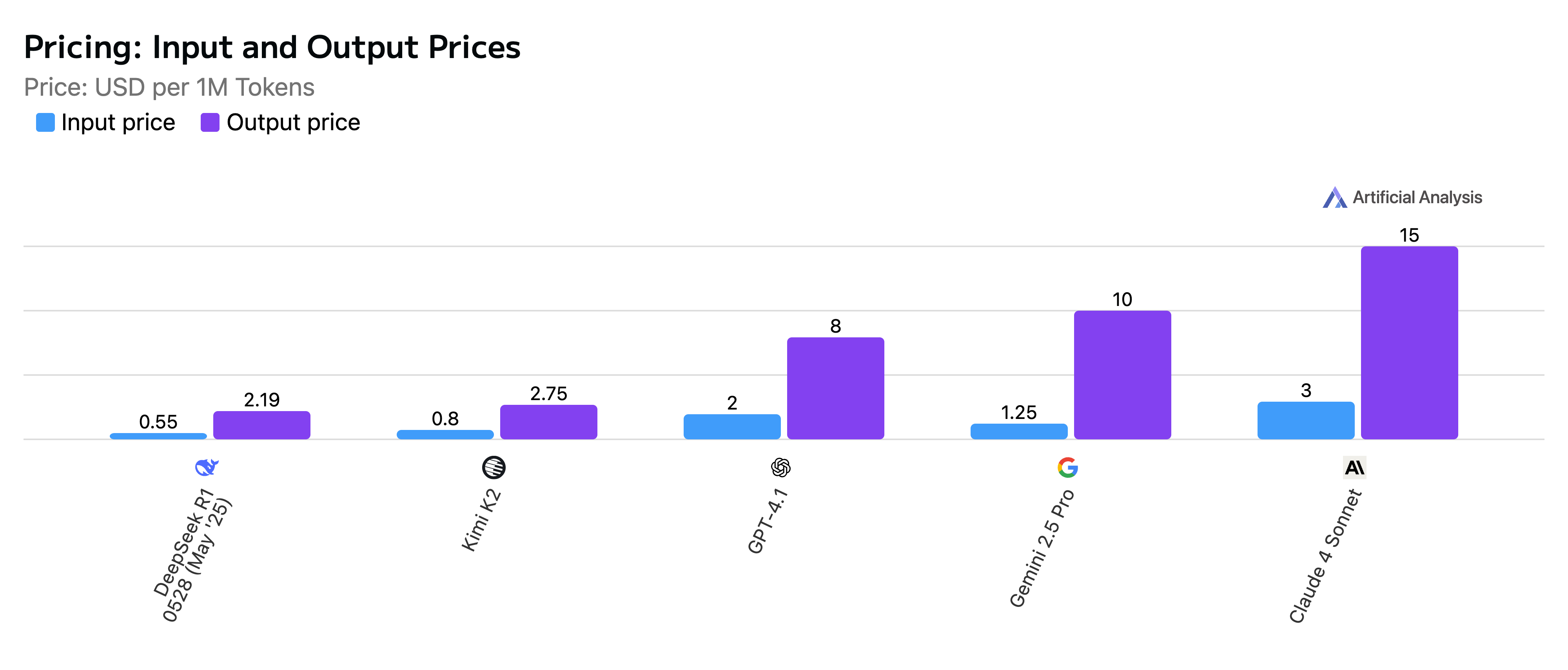
And compare intelligence on a log scale with the cost per token against some of the commercial and open source competition, and an interesting pattern of benchmark-to-price emerges:
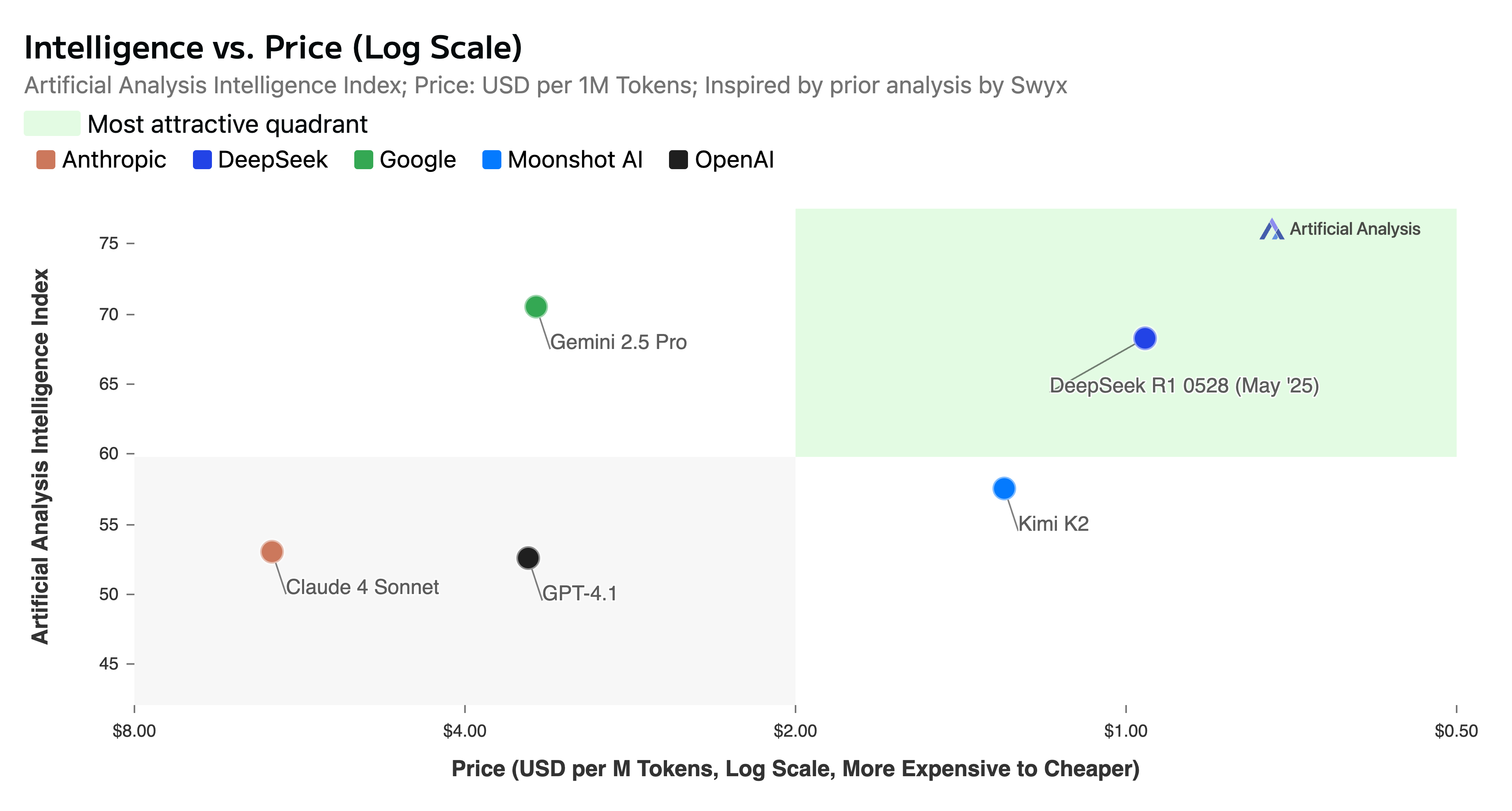
But benchmarks only tell part of the story.
Real-World Testing: Where It Shines and Stumbles
I threw K2 at a practical challenge: enhancing a live web application. Here's what happened:
The Good
Tool execution was surprisingly reliable. Unlike other open models that hallucinate API calls or lose track of context, K2 maintained coherence across multi-step operations. When I needed file modifications, API calls, and database updates in sequence, it handled the complexity without breaking.

Code quality exceeded expectations. The solutions were clean, well-structured, and actually worked. No phantom imports, no made-up functions—just solid, production-ready code.
Judge for yourself - here’s the commit Kimi K2 made to share.kilo.love.
The Struggles
Architectural planning remains weak. Ask K2 to design a solution from scratch, and you'll get something functional but not elegant. It lacks the strategic thinking that makes Claude Sonnet 4 so powerful for complex projects.
Tool use occasionally goes sideways. Once during testing, K2 got lost in a recursive loop, calling the same API endpoint repeatedly. Recovery required manual intervention.

The Sweet Spot: Orchestrated Intelligence
Here's where it gets interesting: K2 excels as an executor, not an architect.
The winning combination? Use Sonnet 4 to design the approach, then hand execution to K2. Sonnet 4 breaks down the problem, identifies the tools needed, and creates a clear plan. K2 takes that plan and implements it reliably.
This isn't a weakness—it's a feature. You get Claude-level strategic thinking at premium pricing for planning, then shift to cost-effective open source for the heavy lifting. That’s one of the key methods I recently wrote about to control your AI spend.
Below you can see a quick example of how to specify what model (configuration profile) to use with each mode:
The Bigger Picture: A Potential Watershed Moment
In a recent video, Theo (of t3.chat fame) argues that K2 could be as transformative as DeepSeek R1—not for the hype, but for its long-term technical impact. Just as R1 ushered in the reasoning era by providing open access to reasoning data, K2 could democratize reliable tool calling. For the first time, developers can generate unlimited high-quality tool calling examples to train other models. This could break Anthropic's current moat in tool reliability and accelerate the entire industry's capabilities in agentic AI applications.
The Provider Puzzle
Since K2 is open source, different providers implement it differently:
OpenRouter: Most flexible routing, but costs (and context window, and TPS) will vary because of it
Groq: Blazing fast at ~250 TPS, but higher latency for initial response
Moonshot AI: Direct from source, full feature set
Context windows vary from 63K to 131K tokens depending on the provider. Throughput ranges from 7 TPS to 152 TPS. Choose based on your speed vs. cost priorities.
Not Quite "Open Source"
Fair warning: K2 uses a modified MIT license requiring attribution if your product exceeds 100 million users or $20 million monthly revenue. It's "open weights" rather than truly open source, but for most use cases, that distinction won't matter.
Why This Matters
K2 represents an inflection point for open models. For the first time, an open weights model can handle complex, multi-step tasks without constant hand-holding. It's not replacing Claude Sonnet 4 for strategic work, but it's making high-quality AI execution accessible at open source prices.
The combination of strong tool use, reliable code generation, and multiple provider options creates real alternatives to closed models. That's good for competition, innovation, and your budget.
Getting Started
Want to try K2?
K2 won't replace your premium models overnight, but it'll handle more of your workload than you expect. Sometimes the best tool isn't the smartest one—it's the one that reliably gets the job done.
The AI landscape keeps evolving fast. K2 proves open models are finally catching up where it matters most: real-world reliability. That's worth paying attention to.
Great analysis! This matches my usage too. It's a little dumber than Claude, but 4x faster and cheaper is very compelling.
Every open source model is not performing well in terms of architecture and critical logic implementation. Hope it improves soon. Great to read it Brendan 😃