
Kilo Code v4.79.1…v4.81.0: Usage-based AI model price estimates, a new Qwen3 Coder Provider, GPT-5 Fixes
5 releases. 3 unique features.

A lot of you probably know Kilo Code as a product that combines features from open-source projects like Roo Code and Cline.
This release also includes features that are unique to Kilo Code (at the time of this writing). Here are the top 3:
The Kilo Code API provider now displays AI model price estimates based on real-world usage
When using the Kilo Code API provider, you can now go to Settings -> Providers and see this data:
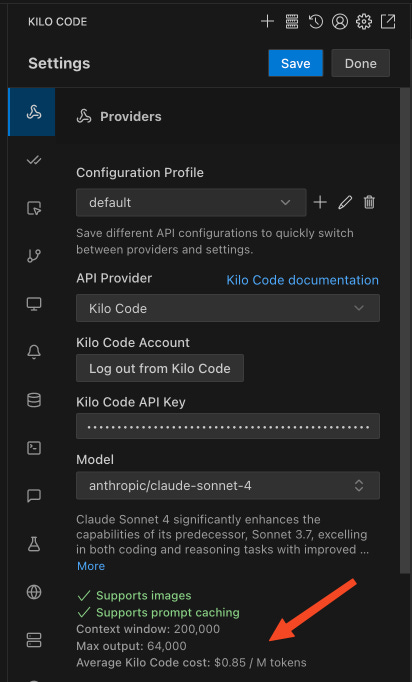
This shows you the average cost (per million tokens) for that particular model based on real usage (people spend over 30 billion tokens per day using the Kilo Code API provider.
This cost estimation also accounts for things like cache discounts as well (thanks @chrarnoldus!)
Why you should care: It’s hard to calculate how much it costs to use a particular AI model if you look at the AI model price list alone (input/output/cache tokens, etc.).
This will give you a better idea on how much you’re expected to spend, based on how much thousands of other Kilo Code users are actually spending right now (you can also use this data for realistic price estimates when using Cline or Roo Code + an external API provider).
For example, at the time of this writing, Kilo Code users are (on average) spending $0.85 per million tokens on Sonnet 4, when using the 200k context window. These are the official API prices for Sonnet 4 ($3 for 1M/input tokens, $15 for 1M/output tokens, $0.3/cached tokens, etc.) As you can see, the math can get really messy, really fast. This provides you a single, accurate number you can use as a “benchmark” on how much you could actually spend.
Added support for Qwen Code as an API provider
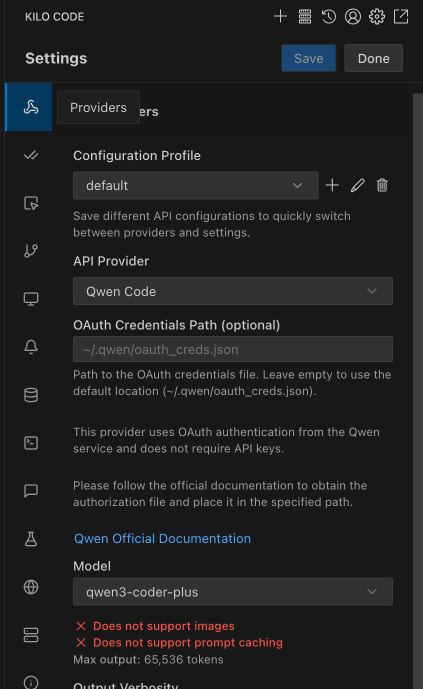
An external contributor (thanks Toukaiteio) just merged a feature where you can use Qwen3 as an API provider inside Kilo Code. Qwen currently has a generous free tier where you can send up to 1000 daily requests to Qwen3 Coder, without token limits.
How to get started; This integration works out-of-the-box; first install Code and create an account. After that, change your API provider to Qwen Code inside Kilo Code (see the screenshot above) and your model to Qwen3 Coder. Kilo Code should automatically find your config Qwen Code file. Get back to the main window and start typing!
Drag-to-pan in the Task Timeline header
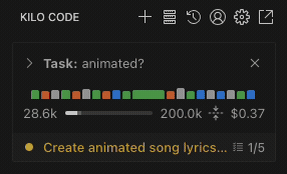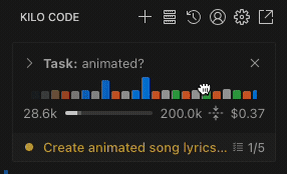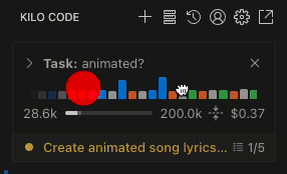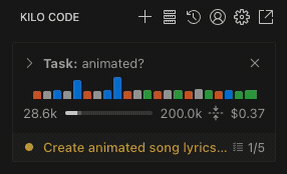
The most colorful feature of Kilo Code has just received an upgrade (thanks @hassoncs!)
The task timeline allows you to easily jump between different chat messages in a task.
That’s it for unique features!
Kilo Code also cares about UX and we have one commonly used feature that we made more easily accessible:
You can now conveniently choose your inference provider for each AI model
Background: An inference provider is a computer (or a set of computers) that runs the AI model (take a look at this article to understand the connection between AI models, inference providers and a consumer app such as Kilo Code).
Why you should care: When you run an AI model (especially an open-source AI model such as Qwen3-Coder), you want it to be cheap, fast and have a decent context window.
The (first) feature: For that reason, we’ve made it easy for you to see the pricing for each inference provider for a particular model.
To access that inference provider data, look for this text under “Settings -> Providers” (and then click on“Provider Price and Capability Breakdown”). You should see this table (this particular table is a list of inference providers for Qwen3-Coder):
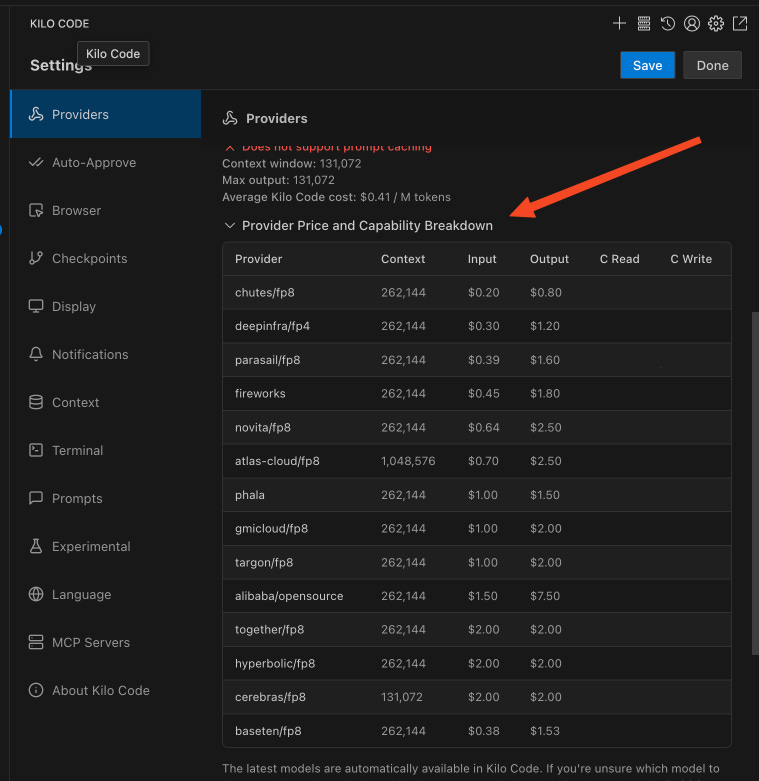
Notice the different prices and context windows sizes? Qwen3-Coder is an open-source AI model, so you have different “hosting/inference providers” who provide access to it at different prices (you can see even more data about these inference providers on OpenRouter).
After deciding what inference provider you’ll use for your AI-model-of-choice, you can deliberately pick either the provider itself, the category of providers you want us to pick for you.
The (second) feature: We now provide an easy way to change an inference provider for a model (note: We already had this feature but it was buried, so we made it more visible & more convenient to use):.
Here’s an example:
As you can see, after you click on the dropdown under “Provider Routing”, you have 2 categories of options:
Let Kilo Code choose the best provider for you, based on your preference for:
Lower price (sacrifice on quality/throughput, but always choose the inference provider with the lowest price)
Higher throughput (could sacrifice on price, but you’ll get the fastest provider)
Lower latency (usually goes hand-in-hand with throughput, but we may choose more expensive inference provider)
Choose the inference provider yourself by just selecting its name from the list. This is great if you’ve done your research and picked the inference provider you want to go with.
Thank you @chrarnoldus for the PR that made all of this possible.
Improved support for GPT-5
Our extension supports over 20 different providers and hundreds of different LLMs models. Adding an LLM is one thing; making sure it works with all features of your extension is an ongoing process. These features are around making sure GPT-5 works with Kilo Code:
#1911 (Thanks @chrarnoldus!) – Fixed Enhance Prompt and Commit Message Generation for GPT-5 on the OpenAI provider.
#1871 (Thanks @kevinvandijk!) – Pulled in Roo Code v3.25.10, these are changes for better GPT-5 support (thanks Cline and @app/roomote!).
🔄 Other provider changes
#1924 f7d54ee (Thanks @chrarnoldus!) – The dedicated Big Model API provider is gone. Use the Z.AI provider with open.bigmodel.cn instead.
#1948 (Thanks @hassoncs!) - Feature: Support drag-to-pan in the Task Timeline header
🛠 Other fixes & updates
These are small fixes/updated that quickly add up to a better user experience:
#1968 (Thanks @chrarnoldus!) - Fixed: OpenRouter routing settings are no longer randomly reset
#1899 (Thanks @ivanarifin!) - Fix: Improve virtual quota fallback handler initialization and error handling
#1955 (Thanks @hassoncs!) - Fix: Add Max Cost input to the AutoApprove menu in the ChatView
#1892 (Thanks @chrarnoldus!) – Fixed not being able to set the Max Auto-Approve Cost.
#1889 (Thanks @unitythemaker!) – The Chutes model list has been updated.
#1879 (Thanks @possible055!) – Updated the Traditional Chinese translations for the Settings UI.
The fixes/updates below were pulled from Roo Code v3.25.10:
#4852 (By @hannesrudolph) – Fix: Use CDATA sections in XML examples to prevent parser errors (this change was pulled from Roo Code v3.25.10)
#6806 (@markp018, PR by @mrubens) – Fixed rounding issue with max tokens.
#6753 (by @alexfarlander, PR by @app/roomote) – Added GLM-4.5 and OpenAI gpt-oss support to the Fireworks provider.
UX improvement – Clicking the plus button in the extension menu now focuses the chat input (thanks @app/roomote!).