
Who makes money from open-source AI models?
Hint: It's those who run the models, not those who make them.

July has been a busy month in the open-source AI model space. Several promising open-source AI models were released in quick succession:
Kimi K2 (July 12) — 32 billion activated parameters, optimized for agentic tasks
Qwen3 Coder (July 22) — Alibaba’s latest coding model
GLM-4.5 (July 28) — an AI model that *almost* matches Sonnet 4 in coding benchmarks
GPT-OSS (July 29) — OpenAI’s first open-weight model.
I’ve been following this whole industry quite closely because a lot of people are using Kilo Code with these open-source models.
In the process, I’ve discovered a group of “hidden players” that are actually monetizing these models; and no, it’s not the AI model creators themselves.
Before getting started, let’s explain the 3 different layers of the “open source AI models” stack:
Layer 1 — The Model Itself
This is the core “intelligence”, the LLM itself, trained on a vast dataset of text.
You can self-host most open-source AI models; however, you’ll need a powerful computer to get it to run fast. Most people move to “Layer 2”:
Layer 2 — The Inference Provider
This is where things get interesting. An inference provider is a service that provides you access to the pre-trained model. They have their own hardware setup to make running the model as efficient & fast as possible.
Some model creators also act as inference providers, for example:
Zhipu AI runs GLM models on its own infrastructure.
Alibaba Cloud also runs their Qwen models.
Here’s where things get interested: There’s also a growing market of independent inference providers like Groq, Cerebras, Chutes, and so on.
Just to give you an idea, OpenRouter’s Kimi K2 page lists at least six different inference providers for the same model (that list is growing by the day):
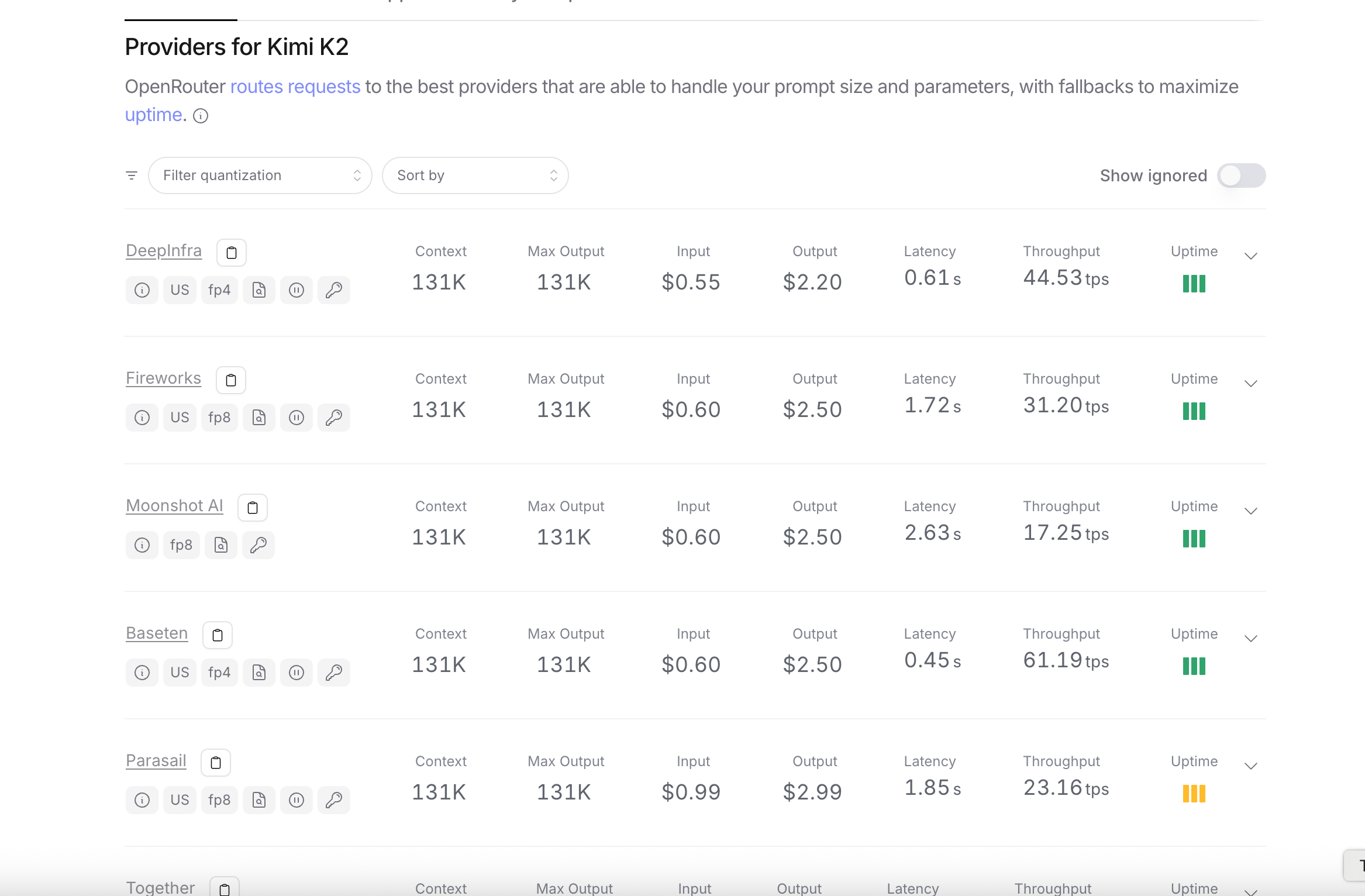
Those inference providers get ranked by several criteria, depending on how fast/reliably they provide access to the underlying model:
Context size – Max input tokens the model can process at once.
Max output – Max input tokens it can generate in a single call.
Input cost – $ you get charged per 1M input tokens.
Output cost – $ you get charged per 1M output tokens.
Latency – Median time until the first token arrives.
Throughput – Tokens per second (tps) once streaming starts.
Uptime – Reliability percentage over time.
Inference providers differentiate a lot: some providers are lightning-fast at off-peak times, but slow down during heavy demand. Others (like Cerebras) charge more but maintain consistent, high-speed responses — sometimes 10× faster than the cheapest option.
Layer 3 — The Consumer Application
The last layer is the interface where you actually use the model. Tools like Kilo, Cline, and Roo, which handle prompt construction, tool integration, etc.
Kilo Code has been the #1 app on OpenRouter for several days now.
Layer 2 generates the most revenue from open-source AI models
With closed-source AI models from Anthropic or OpenAI, it’s the model creator itself that captures the most revenue. You pay those companies directly to get access to their models.
With open-source AI models, the AI model creator doesn’t have “exclusive rights” to run the model. That’s where inference providers step in. Those inference providers own the hardware and run those models on that hardware; you pay access to a “ready to produce output” version of that model.
As we’ve seen, there are many inference providers for the same model. For example, OpenRouter lists 9 inference providers for Qwen3. That figure is similar if you check other major OSS models (Kimi K2, GLM 4.5, etc.)
You can pay those inference providers:
Directly. They usually charge per-million tokens, depending on the models. Some inference providers like Cerebras are trying flat-fee pricing models; for example Cerebras Code, where a monthly fee gets you better per-million token rates.
Through a “reseller” like our Kilo Code provider (that only work with Kilo Code) or OpenRouter. OpenRouter takes a 5% fee, we take nothing because the whole goal is to use the provider to make it more convenient to use the free extension.
GPU resellers. There are inference providers like Chutes, where you pay a lot less less per-million-tokens. The reason for this is that Chutes does not have servers; instead, you have “miners” who contribute GPU compute to Chutes for running the models. In exchange, those models get paid in crypto tokens. Chutes acts as a “middleman” between the GPU miners and you. Of course, security/privacy is a major issue here.
Why you should care about all this
If you’re using agentic coding tools (like Kilo Code, Cline or Roo Code), your experience depends as much on the inference layer as on the model. Picking the wrong provider can mean:
Subpar & slow experience.
Not getting the full power of the model itself. Some providers don’t support caching; some deploy the open-source model in a suboptimal way, etc.
Running out of context window mid-session. Different inference providers provide different context window sizes for the same model; Cerebras, for example, has a 131k token window for Qwen3. The others are 262k tokens.
When using Kilo Code you can also choose your inference provider when running an open-source model:
Hope you found this article to be useful!
As always, wonderful job. Thanks, Darko!