
GLM-4.6 Lands in Kilo Code
Near Claude Parity at a Fraction of the Cost

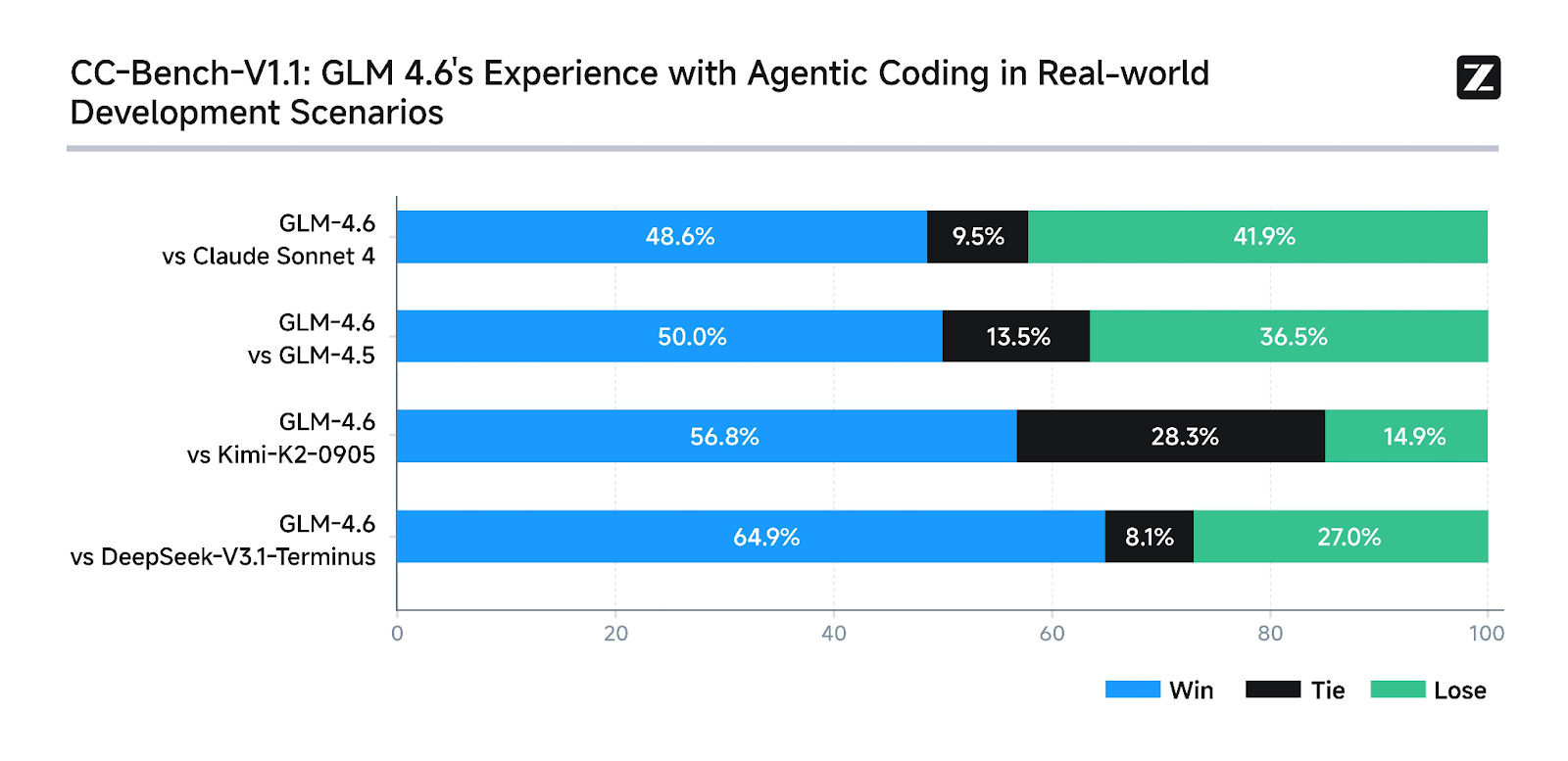
GLM-4.6 just shipped with a 48.6% win rate against Claude Sonnet 4 in real-world coding tasks. That’s near-parity performance at one-fifth the cost—$0.60/$2.20 per million tokens versus $3/$15.
The team at z.ai released benchmarks today showing GLM-4.6 matching or beating Claude Sonnet 4 across multiple evaluations. More interesting: it’s completing tasks with 30% fewer tokens than previous versions while maintaining that performance.

The Numbers That Matter
Token efficiency: GLM-4.6 uses about 651,525 tokens per task compared to 800,000-950,000 for other models. That’s not just faster - it’s fundamentally more efficient architecture.
Context window: 200K tokens, expanded from 128K in the previous version. Enough to hold about 25,000 lines of code or 400 pages of documentation at once - but still much lower than the 1 million+ token context windows we’ve seen from larger labs.
Real performance: In practical coding scenarios - the kind where models often hallucinate functions or lose track of context—GLM-4.6 maintains coherence across multi-file operations.
The Pricing Reality Check
The GLM team also recently launched their “GLM Coding Plan“ at $3/month. For developers, that’s the real story here.
Claude Sonnet 4 costs $3 per million input tokens and $15 per million output tokens. At typical usage, you’re looking at 50-100x cost difference. Even if GLM-4.6 only handles 80% of your workload, the math is obvious.
As we’ve written before, choosing the right model for the job will be how developers win in this AI arms race. Tools like Kilo Code let you orchestrate this: use expensive frontier models for architecture and planning, then route implementation work to cost-efficient alternatives. GLM-4.6’s performance-to-price ratio makes it an obvious candidate for that second tier—and at $3/month for “3x Claude Pro” usage, potentially for both.
Benchmarks vs Reality
The formal benchmarks paint a competitive picture:
AIME 25: 98.6% (matching Claude Sonnet 4)
GPQA: 82.9% (competitive with GPT-4)
SWE-Bench Verified: 68.0% (beating several established models)
LiveCodeBench v6: 70.1% (above industry average)
But benchmarks don’t write production code. The real test happens when you’re debugging a race condition at 2 AM or refactoring legacy code that nobody wants to touch.
GLM-4.6 handles these scenarios. It’s not perfect - no model is - but it’s reliable enough for daily development work.
The Transparency Factor
Z.ai did something unusual: they published all their test questions and agent trajectories on HuggingFace. You can verify their claims yourself. Check the actual code GLM-4.6 generated. See where it succeeded and where it struggled.
This level of openness is rare in the AI space, where most providers treat their evaluations like trade secrets.
Getting Started
GLM-4.6 is available now in Kilo Code. Setup takes about 30 seconds:
Open Kilo Code settings
Select GLM-4.6 from the model dropdown
Start coding
No API keys. No token counting. The model handles images, supports prompt caching, and maxes out at 200,000 tokens of context.
Why This Matters
Six months ago, frontier-level coding AI meant frontier-level prices. Today, models like GLM-4.6 are closing that gap fast.
This isn’t about GLM-4.6 “beating” Claude or GPT-4. It’s about having legitimate alternatives that handle most coding tasks at a fraction of the cost. Save the premium models for the truly complex challenges. Use efficient models for everything else.
The landscape is shifting. Models that were unthinkable at this price point six months ago are now available for the cost of a coffee. That changes the economics of AI-assisted development entirely.
The Practical Take
GLM-4.6 won’t replace your favorite model overnight. But at $3/month through the GLM Coding Plan, trying it costs less than your favorite streaming service.
For startups watching their burn rate, for indie developers bootstrapping projects, for anyone who writes code and cares about costs, this is worth your attention. Use low-cost models for routine implementation work and save frontier models for complex architectural decisions—it’s how smart teams optimize both performance and budget.
The model is live in Kilo Code now. Test it on your actual code. See if it handles your specific use cases. Sometimes the best tools come from unexpected places.
No email enviado, diz que aceita imagem, fala de 3 dolares por mês e contexto. Na parametrização do Kilo fala diferente.
Nice update from z.ai