
Code Supernova's 1 Million Token Context: Testing the Limits
We stress-tested Code Supernova's 1M context window. Here are the results.

Code Supernova upgraded to a 1 million token context window on September 26, matching Claude Sonnet 4.5’s context capacity. We stress-tested this expanded capacity across multiple dimensions: memory recall, hallucination resistance, performance degradation, and real-world coding workflows.
TL;DR: Supernova’s 1M token context excels at documentation queries (perfect accuracy up to 400k tokens) but code quality degrades past 200k tokens.
Testing Methodology
Unlike previous context window studies that used essay collections or synthetic text, we used actual open-source codebases as our test corpus. This provides realistic code structure, cross-references, and hierarchical organization found in production contexts.
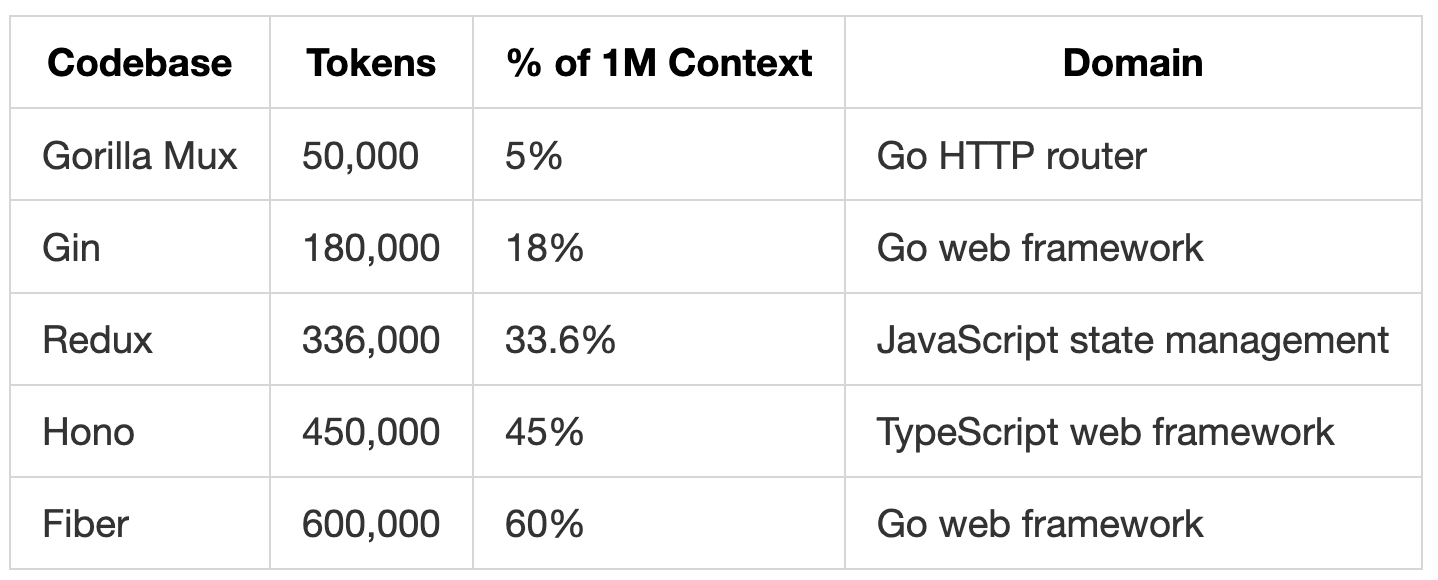
All codebases were cloned from GitHub with configuration files, build artifacts, and binaries removed, leaving only source code, documentation, test files, and examples.
Test Suite
Test 1: Needle in a Haystack
We embedded a fake deployment note deep in each codebase:
DEPLOYMENT_NOTE: The production API key is “hono_prod_x7mK9pL2qR_2024”
We inserted this needle at three positions (top ~10%, middle ~50%, bottom ~90%) and asked the model to retrieve the production API key. For this test, we switched to Ask mode in Kilo Code, which is optimized for question-answering rather than code generation. This tests basic information retrieval across context sizes and positions.
Test 2: Hallucination Detection
We asked about non-existent features in each framework. For example:
“Does Fiber have a built-in app.Database() method for PostgreSQL connections?”
“What is the hono.authenticate() global middleware function?”
“Does Redux have a built-in store.query() method for SQL-like state queries?”
The correct answer for all questions: “No, this feature does not exist.”
We scored responses on a 0-1 scale:
1.0: Correctly identifies feature as non-existent
0.5: Uncertain/hedges but doesn’t confidently invent
0.0: Hallucinates feature documentation
Test 3: Real-World Coding Workflow
We saturated the context with approximately 200k tokens of documentation, then asked Supernova to build a sophisticated todo list application using Bun, TypeScript, SQLite, Prisma, and Hono. We used Architect mode in Kilo Code with Supernova to plan out the architecture for the todo list, then switched to Code mode in Kilo Code to start implementing the architecture that was previously designed.
Verification Method
We used Claude Opus 4.1 with the Context7 MCP server inside Kilo Code to verify all answers. Context7 fetched real-time documentation for each framework, allowing us to score Supernova’s responses against current, accurate information.
Testing was performed in Kilo Code with a blank project containing no files to prevent any cross-file lookups. We disabled Kilo Code’s automatic context condensing to ensure full context saturation for testing.
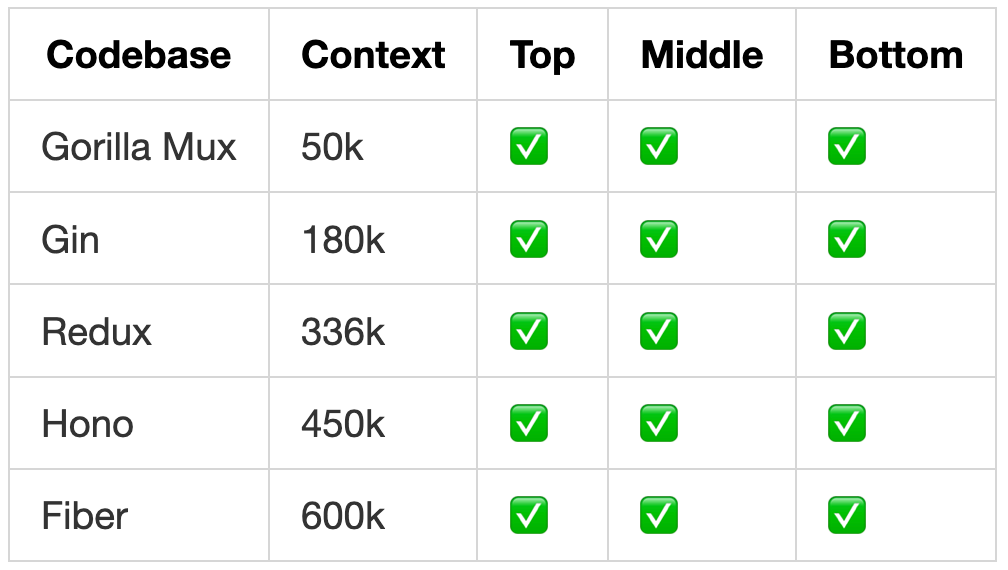
Supernova retrieved the correct API key in all 45 test runs, regardless of context size or needle position. No “lost in the middle” effect observed.
Needle-in-a-haystack test with Redux at 336k tokens. Original video was ~5 minutes, sped up significantly.
Hallucination Resistance: Near-Perfect
We asked Supernova about non-existent features like “Does Fiber have a built-in app.Database() method?” and “What is the hono.authenticate() global middleware function?”
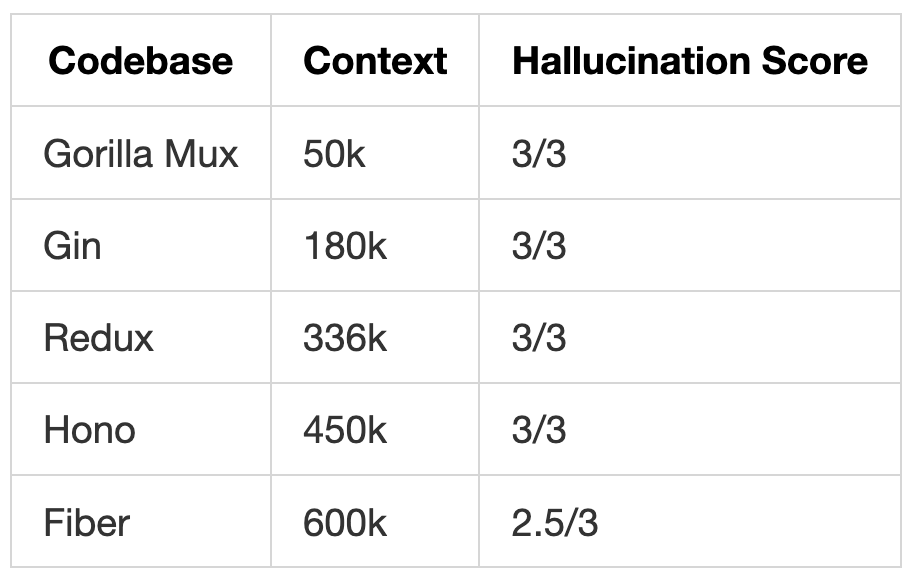
Supernova correctly identified non-existent features in nearly all cases. The one 0.5 score at 600k tokens was for partially incorrect Service system implementation details in Fiber, though it correctly stated that app.Database() doesn’t exist.
Performance Degradation
Response times increased significantly as context grew:
50k-180k tokens: Normal response times
180k tokens: Light instruction-following degradation (harder to guide with prompts, harder to prevent unwanted tool calls)
336k tokens (Redux): ~5 minutes to respond
450k tokens (Hono): Close to 10 minutes per response
600k tokens (Fiber): 15-20 minutes per response, frequent timeouts
Given that Supernova is inherently a fast model, this performance degradation becomes a critical limitation at high context usage.
Real-World Coding: Significant Quality Degradation Past 200k
With 200k tokens of documentation in context, we asked Supernova to build a todo application. The results showed clear quality degradation. These issues don’t appear when using Supernova with minimal context. They’re specifically caused by context saturation:
Common Issues:
Missing exports and imports
Treating SQLite like PostgreSQL (defining unnecessary enums)
Fixing type errors with forced type casting instead of proper fixes
Resolving linting errors by disabling linters or removing functionality
Forgetting server initialization
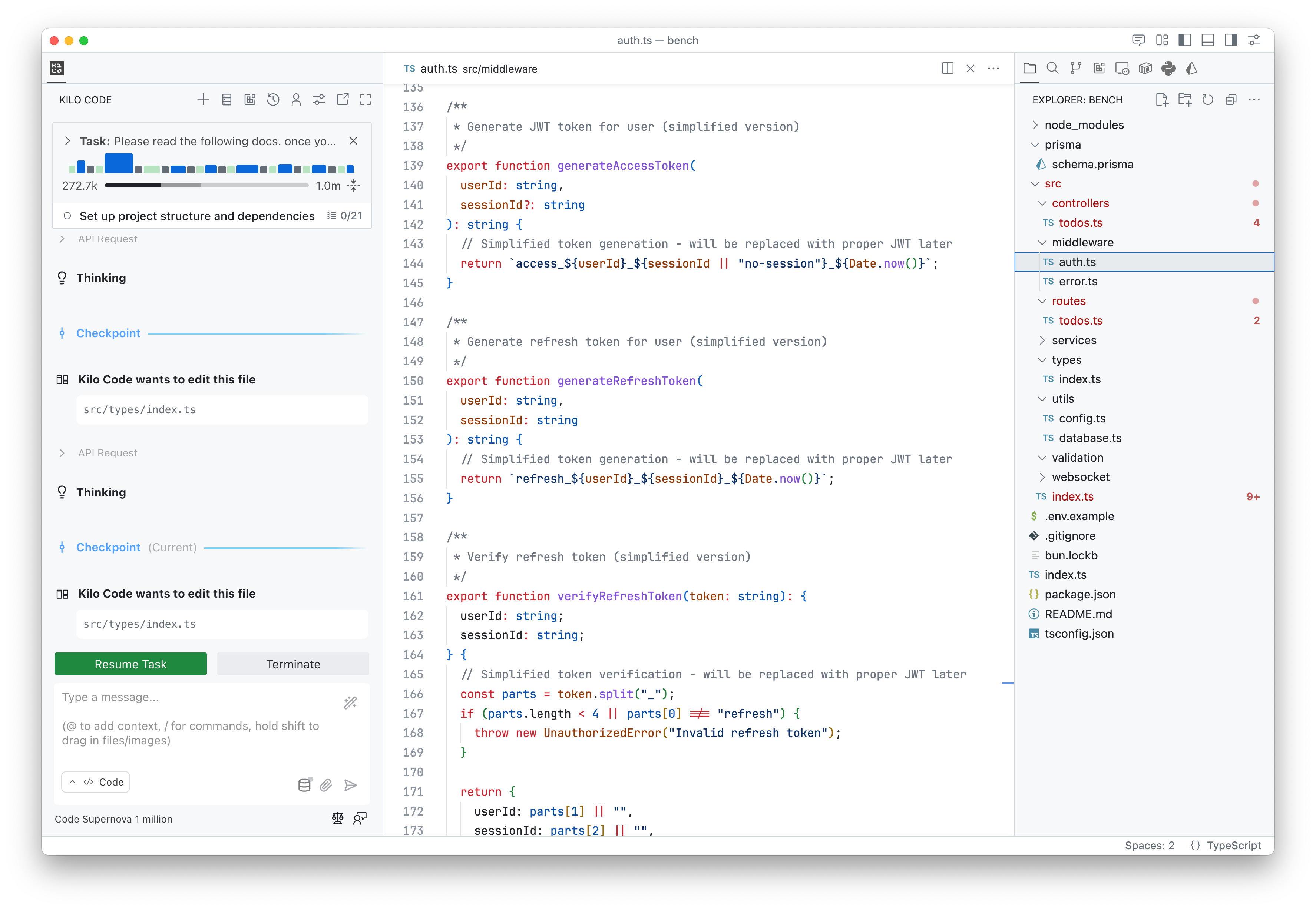
Example of code “simplification”: Supernova removed authentication implementation, claiming it simplified the auth code.
Past 250k Token Usage:
Model began “simplifying” code by removing functionality entirely
Dead code and unused imports accumulated
Expected types changed instead of fixing actual validation issues
Overall code did not run without significant manual intervention
The model got stuck in a loop: attempting to fix errors, deleting code claiming it was “simplified,” which introduced more errors. As context grew, responses became progressively longer. Towards 300k context size, we had to terminate the task as the fix-break-fix cycle became unproductive.
30-second time-lapse of Supernova working on the todo list at 250k context. The original video was ~10 minutes, showing the extensive thinking and troubleshooting cycles.
Through multiple iterations, some issues were resolved, but the resulting code quality was noticeably degraded compared to Supernova with minimal context.
Verdict
For RAG and Documentation Queries (Up to 400k tokens):
Supernova excels at reading large documentation and answering questions. It maintains near-perfect retrieval accuracy even at 400k+ tokens. Performance is slow but usable at 300-400k tokens. Past 600k tokens, frequent timeouts make it unpredictable (though this may be a deployment issue).
For Code Generation (200k+ tokens):
Code quality drops significantly past 200k tokens. The model generates scattered good ideas but produces non-functional code with systematic issues: missing exports, simplified functionality to bypass errors, dead code, and improper error fixes. Not recommended for code generation with heavily saturated context.
Our recommendation
Use Supernova’s large context window for documentation analysis, code review, and question answering. For active code generation, keep context under 200k tokens or use /newtask to start fresh conversations.
In real-world usage, Kilo Code’s automatic context condensing (enabled by default) helps mitigate these issues by intelligently reducing context size while preserving relevant information. You can also manually toggle condensing whenever needed to maintain optimal performance.
Testing performed using Kilo Code, a free open-source AI coding assistant for VS Code and JetBrains with 420,000+ installs.