
Code Supernova is shutting down. Here's what to use instead
We offer 1 free and 1 cheap but good model as an alternative. Here's how they compare to Code Supernova.

As of now, Code Supernova is no longer available in Kilo Code. Code Supernova was the second most-used model on the platform.
Now that it’s no longer available, the question is:
Is there a comparable free model (or a mix of free and paid models) that performs as well or even better than Code Supernova?
We did some benchmarks against a free model (Grok Code Fast 1) and a cheap model (GPT-5 Mini) to find that out. The results surprised us.
TL;DR: Code Fast 1 performs on par with Code Supernova while generating cleaner code. Our tests also found that pairing GPT-5 Mini for planning with Grok Code Fast 1 for implementation creates an affordable workflow that delivers much better code than using either model alone.
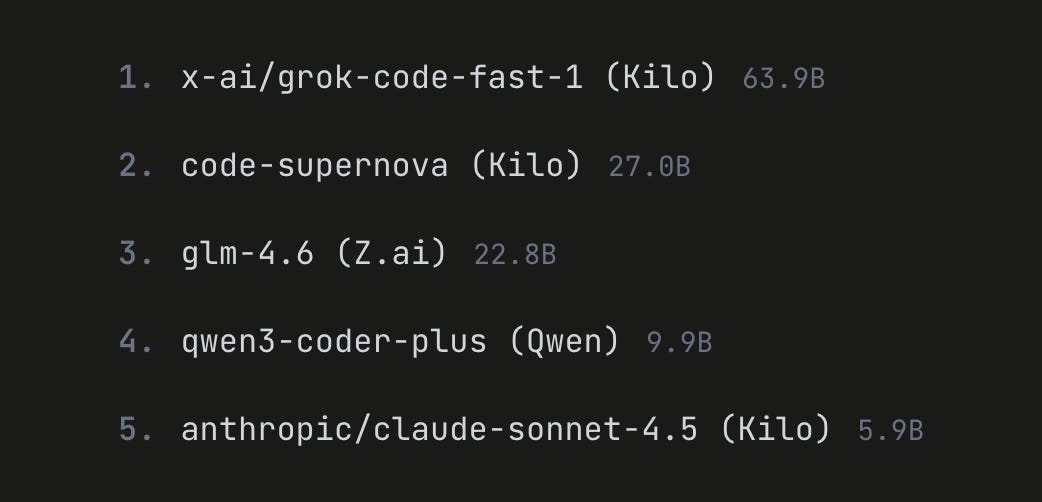
Grok Code Fast 1 vs Code Supernova
We tested both models using our standard job queue benchmark with Bun, TypeScript and SQLite. We’ve been using this same test across multiple model comparisons, making it one of our main benchmarks for evaluating models.
Note: xAI has been constantly improving Grok Code Fast 1, without versioning it. A month ago, Code Supernova might have still held the edge.
Here’s the prompt we use across our tests:
Create a job queue system in TypeScript that uses SQLite as the persistent storage layer. The queue should support:
1. Adding jobs to the queue
2. Processing jobs from the queue
3. Scheduling jobs to run at a specific future time (delayed execution)
Your implementation should handle basic queue operations and ensure jobs are persisted to the database. Include a simple example demonstrating how to use the queue.Solo Performance
We tested each model individually in Code mode, giving them the prompt directly without any planning phase:

Both models delivered working code with different approaches; Grok’s implementation was more compact at 103 lines versus Code Supernova’s 118, with a cleaner API design.
Where Code Supernova bundled everything into a single payload parameter, Grok Code Fast 1 separated job type from job data, making it easier to categorize and route different job types.
Grok Code Fast 1 also used a simple millisecond delay parameter for scheduling (just pass the number of milliseconds to wait), while Supernova required creating Date objects and converting between JavaScript milliseconds and Unix seconds.
These design choices resulted in a simpler API that was 15 lines shorter.
Where Grok Code Fast 1 Performed Better
Separate type and data parameters: Grok used addJob(type, data, delay) with distinct parameters for job type and payload. Code Supernova bundled everything into a single payload parameter, requiring developers to implement their own type system within the JSON payload.
Millisecond delay parameter: Grok accepts delay directly in milliseconds (delayMs: number = 0). Supernova required creating Date objects and converting between JavaScript milliseconds and Unix seconds which could be error prone.
Automatic JSON parsing on retrieval: Grok’s getPendingJobs() returns objects with parsed JSON data ready to use. Supernova returns JSON strings from the database that require manual parsing (except during internal job processing).
Both models delivered working implementations but focused on the core requirements rather than production concerns like retry logic or performance optimization. This led us to test whether a planning phase could help.
The Hybrid Approach: Planning + Execution
This hybrid approach is becoming popular in Kilo Code. Use Architect mode for a separate planning stage, get a clear plan, then switch to Code mode for implementation.
This workflow also lets you use different models for each stage, matching their strengths to the task. We tested GPT-5 Mini, a model that’s been performing really well considering it’s “mini”, for planning and Grok Code Fast 1 for implementation
After combining these 2 models, the results changed dramatically.
GPT-5 Mini costs $0.25/M input and $2.00/M output and with prompt caching ($0.025 per 1 million input tokens), the actual cost is much lower. We ran our queue prompt through GPT-5 Mini in Architect mode multiple times and the cost came out under $0.01 each time.
Combined with Grok Code Fast 1 being free right now, the total cost for implementing this job queue was under $0.01. This pairing offers exceptional value for the quality of code you get.
Hybrid Results vs Solo Attempts

The hybrid approach took longer but delivered significantly better code:
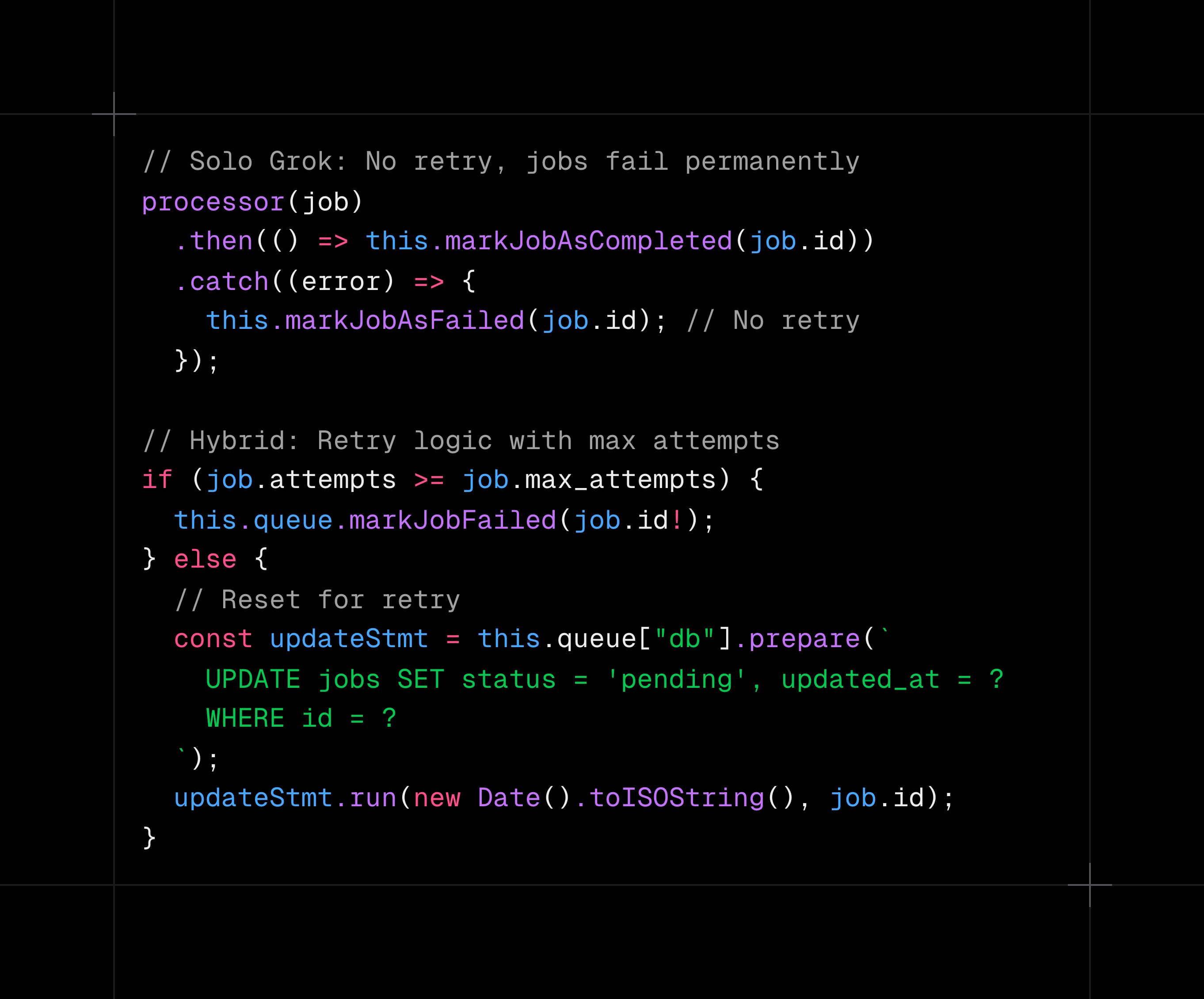
What Planning Added
GPT-5 Mini’s architecture plan included:
Separate Queue and Worker classes
Retry mechanism with configurable attempts
Database indexes for performance
Migration system for schema updates
Proper error handling throughout
Polling worker with lifecycle management
Grok Code Fast 1 then implemented exactly what was planned, producing code with proper architecture and error handling versus the basic implementation from its solo attempt.
Grok Code Fast 1 implementing the architecture planned by GPT-5 Mini.
Recommended Workflow
Developers use language models for two types of tasks:
Small, focused changes like “add caching to this function” or “fix this validation bug.”
Bigger architectural work like “implement this entire API” or “build a notification system.”
For the small, focused changes, Grok Code Fast 1 works great on its own. It’s fast, follows instructions well, and gets you working code in seconds. These are the tasks where you know exactly what you want and just need the model to execute.
For bigger changes that need planning and architecture, the GPT-5 Mini + Grok Code combination might make more sense. GPT-5 Mini thinks through the design, then Grok Code implements it quickly.
This hybrid approach works well for tasks like building a new feature from scratch, designing a database schema, or refactoring a large module. It produces significantly more robust code.
The key is recognizing which type of task you’re facing. If you can describe the change in one sentence and know exactly where it goes, use Grok Code Fast 1 alone. If you’re starting with requirements and need to figure out the approach, start with GPT-5 Mini in Architect mode.
Get Grok Code Fast 1 for free + a lot of GPT-5 Mini usage for $10
Grok Code Fast 1 is currently free in Kilo Code.
GPT-5 Mini costs $0.25/M input, $2.00/M output tokens. While using Kilo Code, about 60%-90% of the tokens you’ll use will be input tokens. 50%+ of those tokens will be cached, and GPT-5 Mini caches input tokens at $0.025, making this model extremely affordable.
How to use GPT-5 Mini for cheap using the Kilo Code gateway: We have a temporary promo where you get $20 in extra credits on your first top-up. For example, topping up $10 gives you $30 total to use across all paid models. That’s 2 months of regular/heavier usage if you combine GPT-5 Mini + Grok Code Fast 1.
To claim this deal, go to your profile page and you’ll see this:
P.S. Join us for a live AMA on our Discord on October 28th at 11 AM EST / 4 PM CET to chat live about everything Code Supernova.