
We compared Claude Haiku 4.5 vs. GLM-4.6 vs. GPT-5 Mini
Which one works the best for coding tasks?

When Anthropic released Claude Haiku 4.5, our users immediately wanted to know:
How does it stack up against GLM-4.6 and GPT-5 Mini?
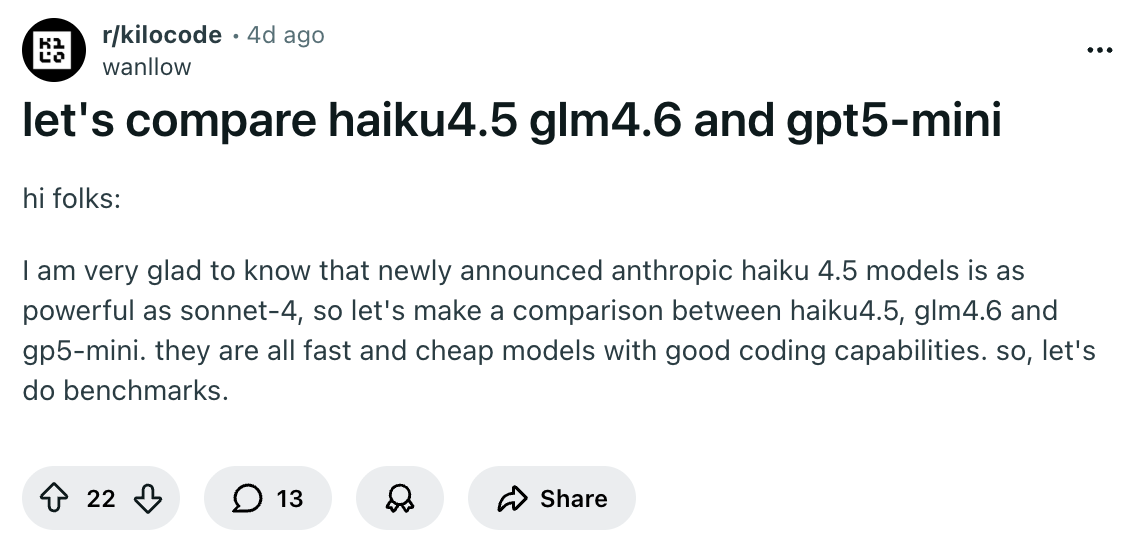
These 3 models fall within a similar price bracket
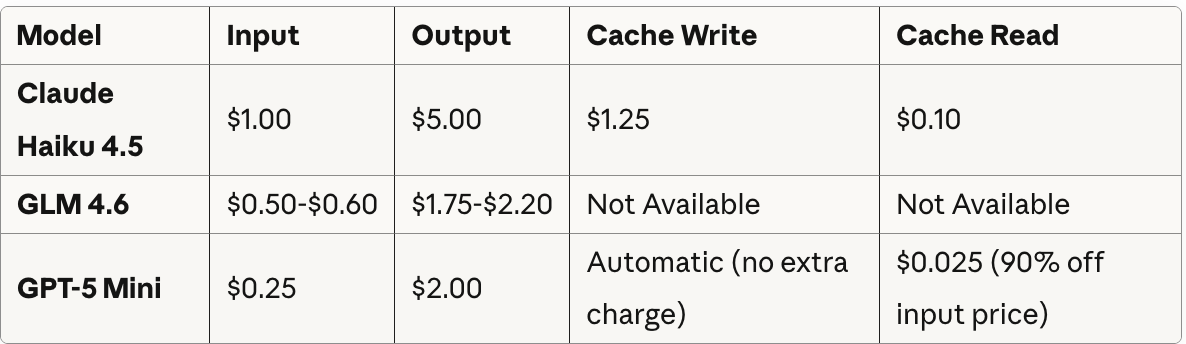
Which model gives you the best bang for the buck when it comes to coding?
To answer this question, we tested all three models by measuring things like speed, cost, code quality, and tool calling.
TL;DR: GPT-5 Mini implemented lease-based locking and delivered the strongest concurrency safeguards (6 min, $0.05). Haiku 4.5 was fastest with the most features and zero tool-calling failures (3 min, $0.08); GLM-4.6 produced multi-file architecture but required disabling reasoning mode for tool calls (4 min, $0.14).
A disclaimer before we start
Before we jump into the results, it’s important to mention that these are mid-tier models optimized for cost and speed rather than maximum capability.
Claude Opus 4.1, Sonnet 4.5, and GPT-5 Codex represent the current frontier models but cost significantly more.
Test setup
We used Kilo Code in Ask Mode (optimized for Q&A) to design the test prompt. The prompt was intentionally clear yet open-ended, evaluating how models interpret requirements and prioritize features like edge case handling, graceful shutdown, and architecture decisions. We deliberately didn’t optimize prompts for individual models—the results show each model’s default behavior and interpretation.
Here is the prompt we used across all three models:
Create a job queue system in TypeScript that uses SQLite as the persistent storage layer. The queue should support:
1. Adding jobs to the queue
2. Processing jobs from the queue
3. Scheduling jobs to run at a specific future time (delayed execution)
Your implementation should handle basic queue operations and ensure jobs are persisted to the database. Include a simple example demonstrating how to use the queue.
For testing, we switched to Code Mode in Kilo Code and ran the same prompt across all three models. Each model started from an identical blank Bun/SQLite/TypeScript project with only the better-sqlite3 dependency installed, ensuring uniform starting conditions across all tests.
The results
We ran this test multiple times with each model and observed consistent patterns across runs:
Performance Overview
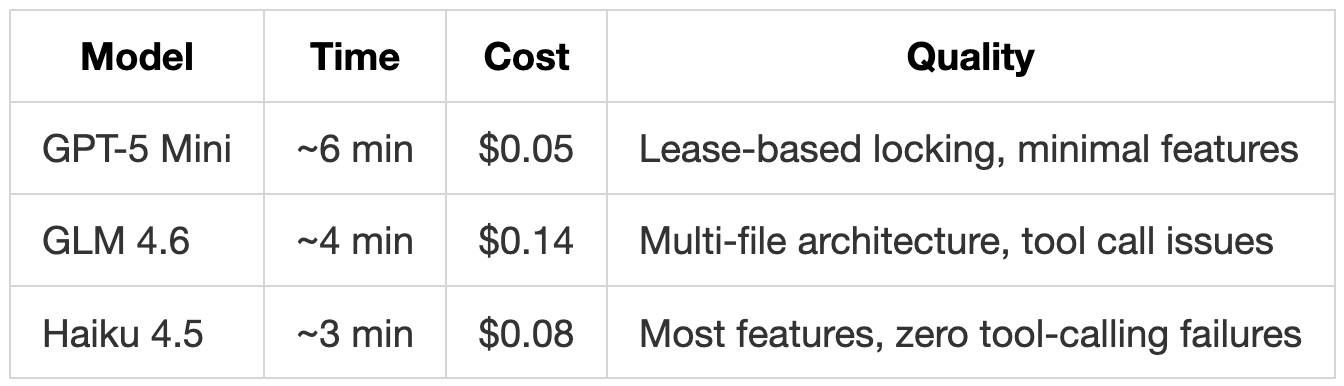
Feature Comparison
To compare features and safety patterns across all implementations, we used Claude Opus 4.1 to analyze each implementation and catalog the features, architectural patterns, and safety mechanisms present in the code.
We then manually verified these findings against the actual code, removed items we considered less relevant for production use, and organized everything into the table below.
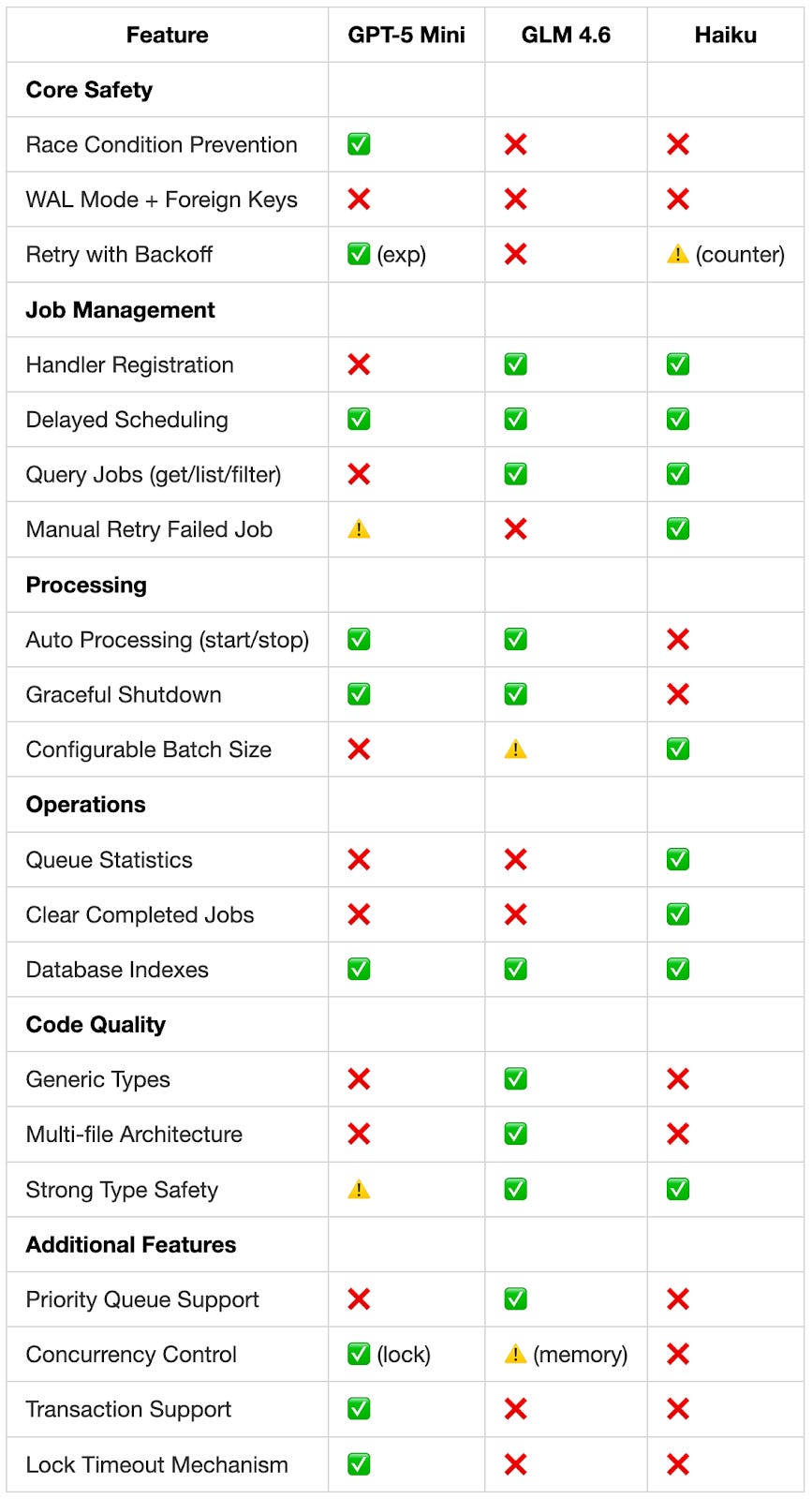
GPT-5 Mini: Testing Observations
GPT-5 Mini took ~6 minutes to generate code at $0.05 (the lowest cost). It was the only model that understood SQLite’s concurrency limitations and worked around them with application-level locking using a timestamp-based lease approach with a locked_until column.
This lease-based locking means jobs get temporary locks that automatically expire if a worker crashes, preventing deadlocks while ensuring jobs don’t get processed twice.
The implementation included transactions, exponential backoff retry with Math.pow(2, attempts), and the most efficient job selection query. While it lacks user-facing features (no stats, no job type registration), it handles the critical safety aspects correctly.
During testing, GPT-5 Mini had a few minor issues with file editing tool calls. We asked it to retry and it successfully generated the code we wanted.
GPT-5 Mini generating the job queue implementation. Original video was ~6 minutes.
GLM-4.6: Testing Observations
GLM-4.6 completed the task in ~4 minutes at $0.14. The code had the best organization with multi-file structure (types.ts, database.ts, job-queue.ts), full type system with enums, and priority queue support.
GLM-4.6 was also the only model to implement priority queues (going beyond the requirements). However, it hand-rolled a UUID v4 generator instead of using built-in crypto.randomUUID() which is a minor nitpick..
It’s worth noting that GLM 4.6-attempted tool calling during the reasoning phase and failed on all our runs. We had to disable reasoning mode (set to minimal) to get it working. This fixed tool calling but hurt performance since we turned off reasoning.
The code demonstrated good separation of concerns with a clean multi-file structure, splitting the implementation across three files. While GLM-4.6 showed conceptual understanding of concurrency by tracking active jobs in an in-memory Set, this approach had a flaw: the tracking wasn’t persisted to the database. This means if a worker crashes, the entire Set is lost, causing the system to lose track of all running jobs.
GLM 4.6 generating the job queue with reasoning mode disabled.
Claude Haiku 4.5: Testing Observations
Haiku generated the entire code in ~3 minutes at $0.08. The code had the most features: stats, retry, job clearing, and database indexes. It was the only model to implement getStats() and clearCompleted() methods (practical housekeeping features that developers actually want in production). The implementation used clear method naming with good code documentation.
Haiku had zero tool-calling failures across all our test runs. Every file edit, creation, and modification worked on the first attempt.
The fastest implementation (3 minutes) came with trade-offs: no concurrency control (could cause race conditions), no transactions, and no job locking (could process same job twice). Instead of running continuously, you have to manually call processQueue() with a batch size. Haiku optimized for getting something working quickly rather than production safety.
It’s also worth noting that Haiku sometimes got stuck in a loop during our testing, repeating the same response.
Haiku 4.5 getting stuck in a loop, repeating the same response multiple times.
Tool Calling Performance
Here’s how each model handled tool calling (reading files, writing files, making edits) within the IDE:
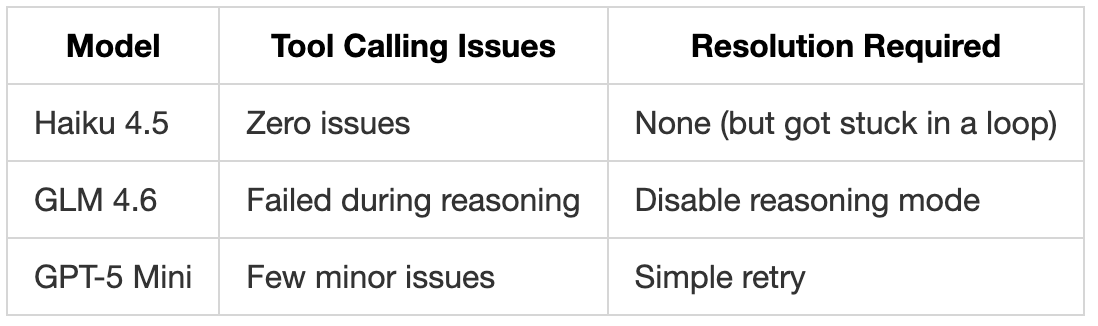
GLM 4.6’s reasoning mode doesn’t work reliably with tool calling. You have to turn off reasoning to make tool calling work. Haiku had zero tool-calling failures across all tests.
Key Findings
Cost vs Quality
We discovered an inverse relationship between cost and quality. The costs shown reflect actual expenses for completing this task, not per-token rates.
This distinction matters because “token hungry” models (those generating lengthy responses or extensive reasoning steps) can be more expensive despite lower per-token pricing.
GLM-4.6 exemplified this pattern: although its per-token rate was competitive, it became the most expensive model due to high token consumption in our tests.
Here are our conclusions:
Cheapest to run ($0.05): GPT-5 Mini delivered the most production-ready code
Most expensive to run ($0.14): GLM 4.6 had the best architecture but missed safety features
Middle cost ($0.08): Haiku provided the most features but no concurrency control
Handling Concurrency
All three models dealt with SQLite’s concurrency limitations differently:
GPT-5 Mini: Implemented application-level locking with timestamp-based leases
GLM-4.6: Attempted in-memory tracking (doesn’t survive crashes)
Haiku 4.5: Didn’t address concurrency at all
GPT-5 Mini was the only model that properly understood SQLite’s limitations and implemented a robust workaround: a lease-based approach that gracefully recovers when workers crash.
Conclusion
Each model made different trade-offs in our job queue test:
GPT-5 Mini ($0.05, 6 minutes): Prioritized correctness and safety at the lowest cost. Built robust concurrency handling through application-level locking with timestamp-based leases. The generated code had the strongest concurrency safeguards of all three models, though with minimal additional features. Had 2 tool-calling failures requiring retries.
GLM 4.6 ($0.14, 4 minutes): Focused on architecture with multi-file structure, full type system, and priority queues. Reasoning mode breaks tool calling, so you have to turn it off for it to work.
Haiku 4.5 ($0.08, 3 minutes): Balanced features and speed with the richest feature set (getStats(), clearCompleted(), configurable batch size). It also had zero tool-calling failures across our runs but missed concurrency control entirely and got stuck in a loop during testing.
All tests were conducted using Kilo Code, an open-source AI coding assistant for VS Code, JetBrains and CLI with over 520,000 installs.