
Future AI bills of $100k/yr per dev
Token growth indicates future AI spend per dev

Kilo just broke through the 1 trillion tokens a month barrier on OpenRouter for the first time.

Each of the open source family of AI coding tools (Cline, Roo, Kilo) is growing rapidly this month.

Part of this growth is caused by Cursor and Claude starting to throttle their users. We wrote about Cursor at the beginning of July and about Claude in the second half of July. Their throttling sent users to the open source family of AI coding tools causing the increases you see in the graphs above. Cursor and Claude needed to throttle because the industry made a flawed assumption.
The industry made a flawed assumption about AI Tokenomics
The industry expected that because the raw inference costs were coming down fast, the applications inference costs would come down fast as well but this assumption was wrong.
Raw inference costs did decrease by 10x year-over-year. This expectation made startups bet on a business model where companies could afford to sell subscriptions at significant losses, knowing they'd achieve healthy margins as costs plummeted.
Cursor's Ultra plan exemplified this approach perfectly: charge users $200 while providing at least $400 worth of tokens, essentially operating at -100% gross margin.
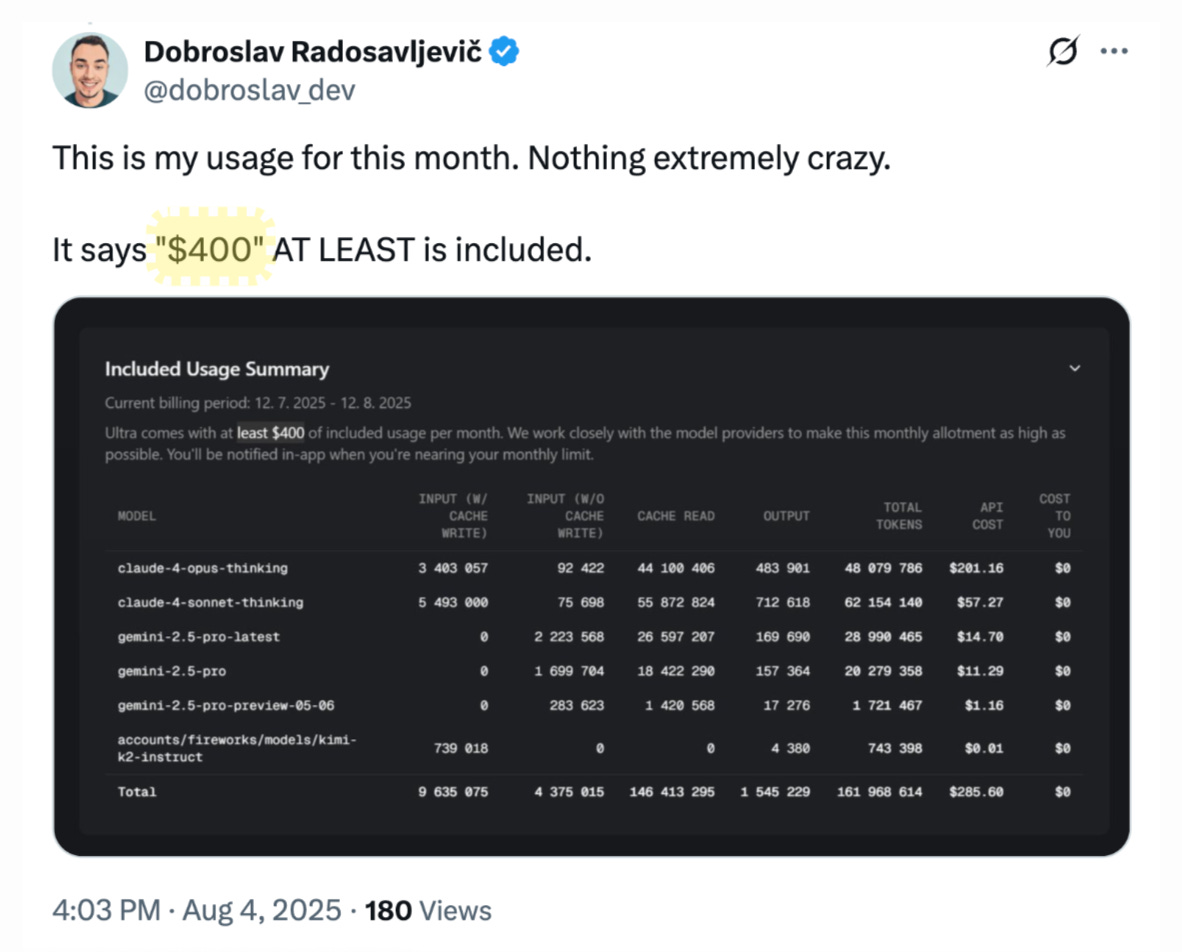
The bet was that by the following year, the application inference would cost 90% less, creating a $160 gross profit (+80% gross margins). But this didn't happen, instead of declining the application inference costs actually grew!
Why application inference costs exploded
Application inference costs increased for two reasons: the frontier model costs per token stayed constant and the token consumption per application grew a lot. We'll first dive into the reasons for the constant token price for frontier models and end with explaining the token consumption per application.
The price per token for the frontier model stayed constant because of the increasing size of models and more test-time scaling. Test time scaling, also called long thinking, is the third way to scale AI as shown in the graphic below.
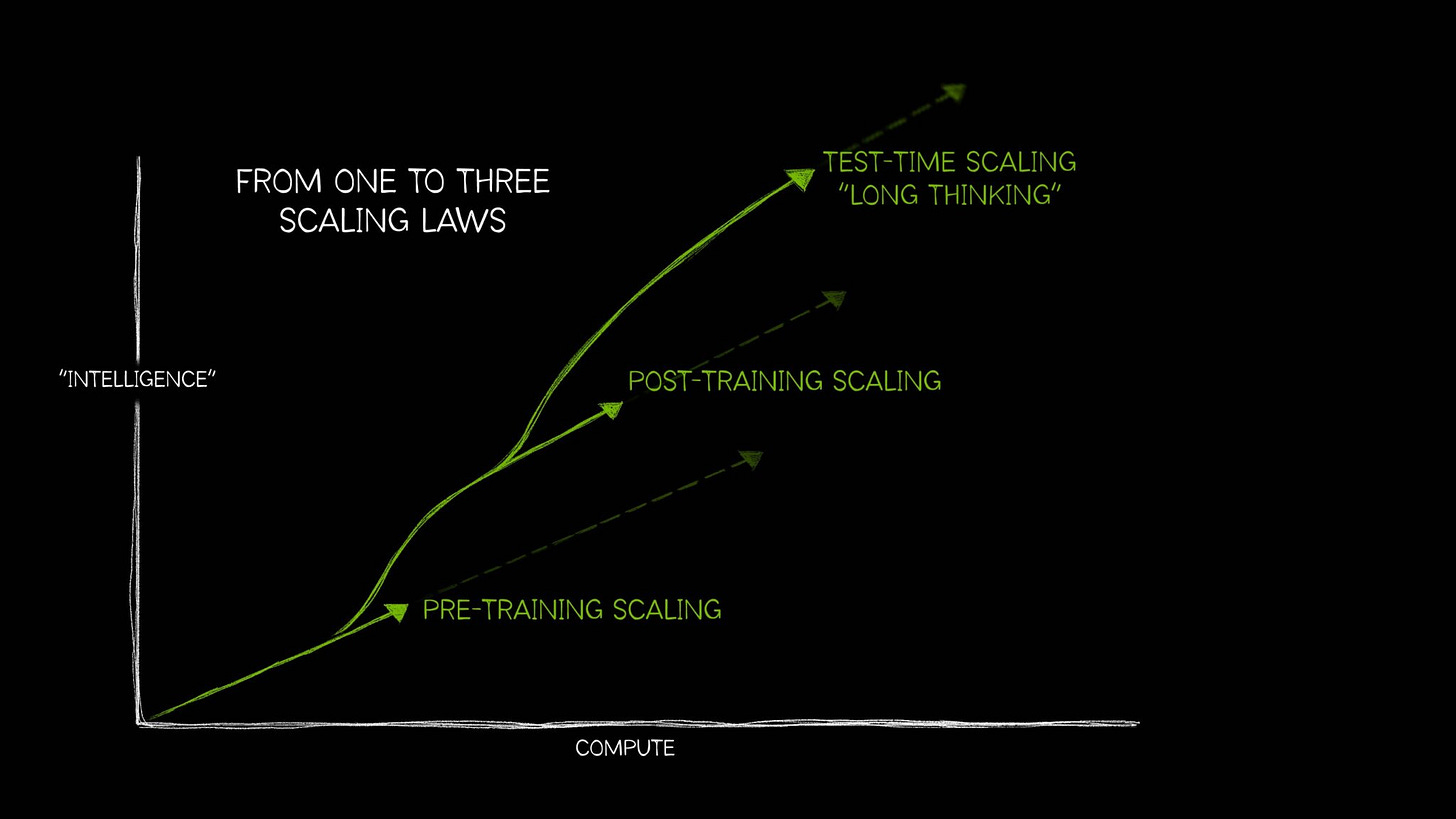
While the pre- and post-training scaling influenced only the training costs of models. But this test-time scaling increases the cost of inference. Thinking models like OpenAI's o1 series allocate massive computational effort during inference itself. These models can require over 100x compute for challenging queries compared to traditional single-pass inference.
Token consumption per application grew a lot because models allowed for longer context windows and bigger suggestions from the models. The combination of a steady price per token and more token consumption caused app inference costs to grow about 10x over the last two years. Market leader Cursor introduced a $200 plan where before $20 was the default. The $200 plan has also been followed by Claude Code and others.
The fixed $200 plan requires throttling the power users
The top end of subscriptions is $200 today but power users find that they are extensively throttled if they use a lot of inference. That throttling comes in the form of rate limiting, using lower quality models, context window compression, and other techniques.
If you don't want to be throttled you need to pay for inference yourself. The open source family of coding tools (Cline, Roo, Kilo) is based on that principle: “never throttle the user”. Because the users directly see the costs these tools have also led the way in reducing costs by allowing the users to:
Splitting work up in many smaller tasks that can each be run efficiently.
Using different modes, in Kilo we have an Orchestrator, Architect, Code, and Debug mode.
Combine closed-source models for architecting tasks (e.g. Sonnet 4) and open-source for coding (Qwen3)
Enhance the prompt with AI before submitting it
Optimize context efficiency with memory banks
Enable prompt caching
Allow termination of a running task when the model hallucinates
Despite the efforts to reduce costs we do expect them to continue to grow for the power users.
App inference cost will continue to grow to $100k+ a year
We expect app inference costs to grow quickly. This is driven by two developments: more parallel agents and more work done before human feedback is needed.
People are experimenting with parallel AI coding agents today with Warp already having it available to people. We expect parallel agents to become the default in the industry and look forward to introduce them in Kilo code sooner rather than later. This will greatly increase token consumption per human hour.
Agents are also able to work longer before needing human feedback. Because they are working more and pausing less this also increases token consumption per human hour.
Both effects together will push costs at the top level to $100k a year. Spending that magnitude of money on software is not without precedent, chip design licenses from Cadence or Synopsys are already $250k a year.
While the prospect of $100k+ per year in costs is a lot it can always be worse.
If $100k inference seems a lot wait until you look at training
AI costs for most engineers are approximately 1000x smaller than what is happening at the AI training stage. Here the costs for the normal 'inference engineer' is dwarfed by the thousand times bigger impact of the AI ‘training engineer’. The ‘inference engineer’ we talked about above might make $100k and use $100k to be many times more productive than an engineer before AI. A top ‘training engineer’ directs $100m in spend and is paid $100m a year. Top frontier labs spend billions on AI training and this compute work is directed by a handful of people. Mark Zuckerberg is rumored to have offered these people ‘signing bonuses’ of $100m to $1b with unknown contract lengths. The difference in pay between inference and training engineers is because of their relative impact. You train a model with a handful of people while it is used by millions of people.
u made this website using kilo code ??
i think your scaling laws graphic should have the arrows extending out of the bottom side rather than the top because the new paradigms take OOM more compute / token burn to try to keep up the "intelligence" scaling