
Cursor Plan Mode vs. Kilo Code Architect Mode
What's the main difference and what can you expect?

This month, Cursor announced Plan Mode, a new feature that allows you to create a plan before the agent starts coding
Kilo Code had an Architect Mode since its launch in March that does a similar thing
We tested our agent vs. Cursor side-by-side to see how they compare, using GPT-5 and Sonnet 4.5. The results were nuanced.
TL;DR: Kilo’s Architect mode averaged 8.7/10 addressing edge cases and error handling upfront, while Cursor’s Plan mode averaged 7/10 favoring simpler architecture plans. GPT-5 provided actionable code snippets and Sonnet included authentication, rate limiting, and visual diagrams.
Testing Methodology
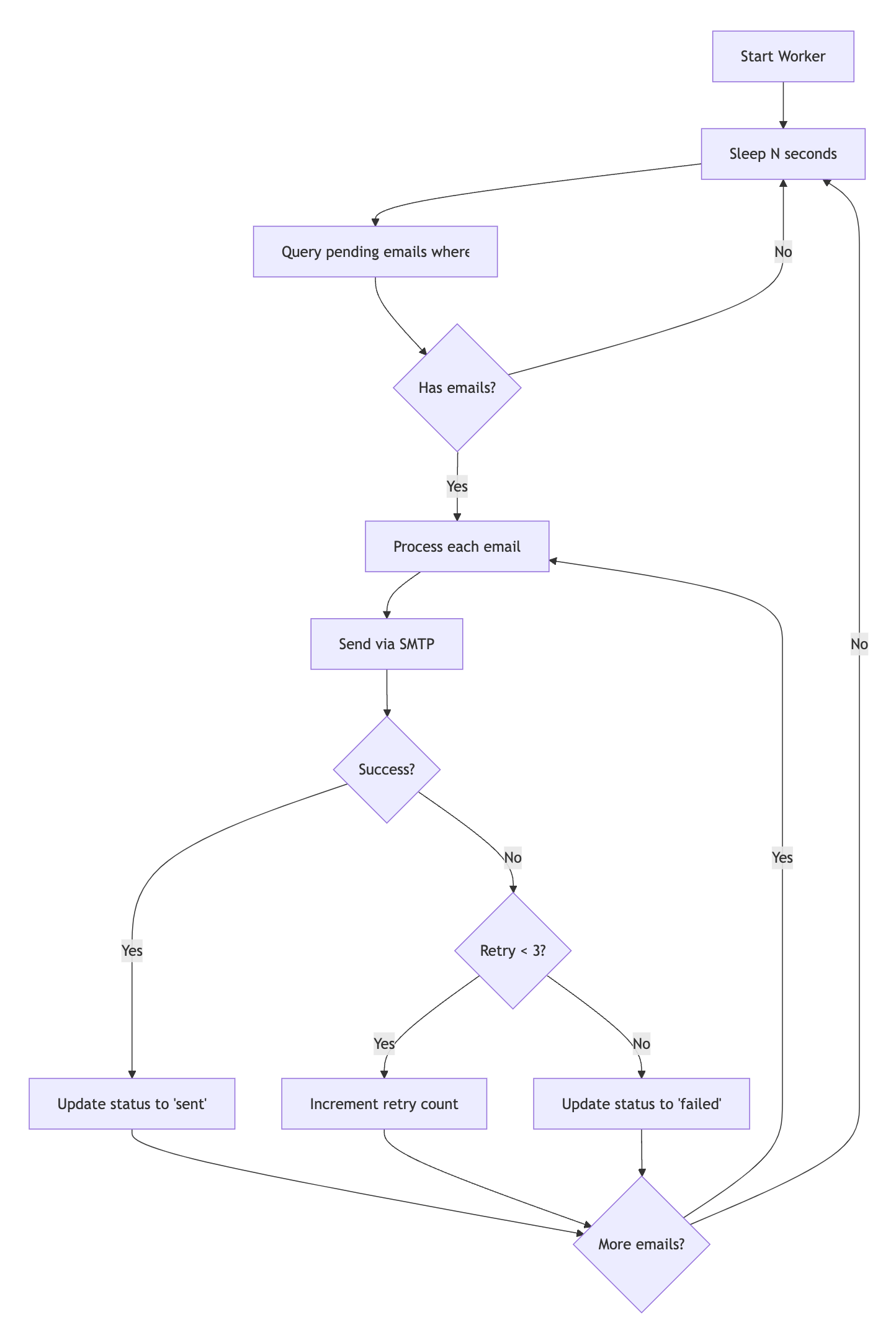
We tested both agents by asking them to design a background email notification service (using Cursor’s Plan mode and Kilo’s Architect mode).
We used the same prompt for both cases:
I’m building a background email notification service using Bun, Hono, TypeScript, and better-sqlite3. It should let me schedule emails with to, subject, body, and sendAt fields, store them in SQLite, and send them later through SMTP. How would you design and implement this?
The test configuration:
Blank Bun + TypeScript project
No additional context or documentation
Testing with GPT-5 (medium reasoning) and Claude Sonnet 4.5
How we scored the output
We evaluated each planning result against these criteria:

Here are the results.
Results by Model
GPT-5 (Medium Reasoning)
GPT-5 consistently produced short, direct plans with code examples across both agents (782 words on average).
Some comments about its output style:
There was a heavy use of code snippets (15-20% of output was actual code)
It used technical shorthand phrases (eg. “Claim → send → finalize loop”)
It also used precise values to describe things (eg. “15,000ms backoff, epoch millisecond timestamps”)
There was minimal explanatory text
In Cursor, GPT-5 provided a basic but functional architecture.
In Kilo Code, the same model added advanced features like randomized retry delays to prevent simultaneous retries; deduplication using message IDs, and atomic job assignment to prevent race conditions between workers
Claude Sonnet 4.5
Claude Sonnet 4.5 delivered more detailed plans with full explanations (averaging 894 words.)
Some comments about its output style:
There were well-organized sections and subsections
It explained the reasoning behind its choices
There were complete directory structures
It also provided testing strategies and future enhancements
Sonnet 4.5 in Kilo’s Architect Mode generated Mermaid diagrams for system architecture and process flows, and incorporated security considerations like rate limiting.
Sonnet 4.5 in Cursor’s Plan Mode provided step-by-step implementation guides and included API key authentication via `x-api-key` headers.
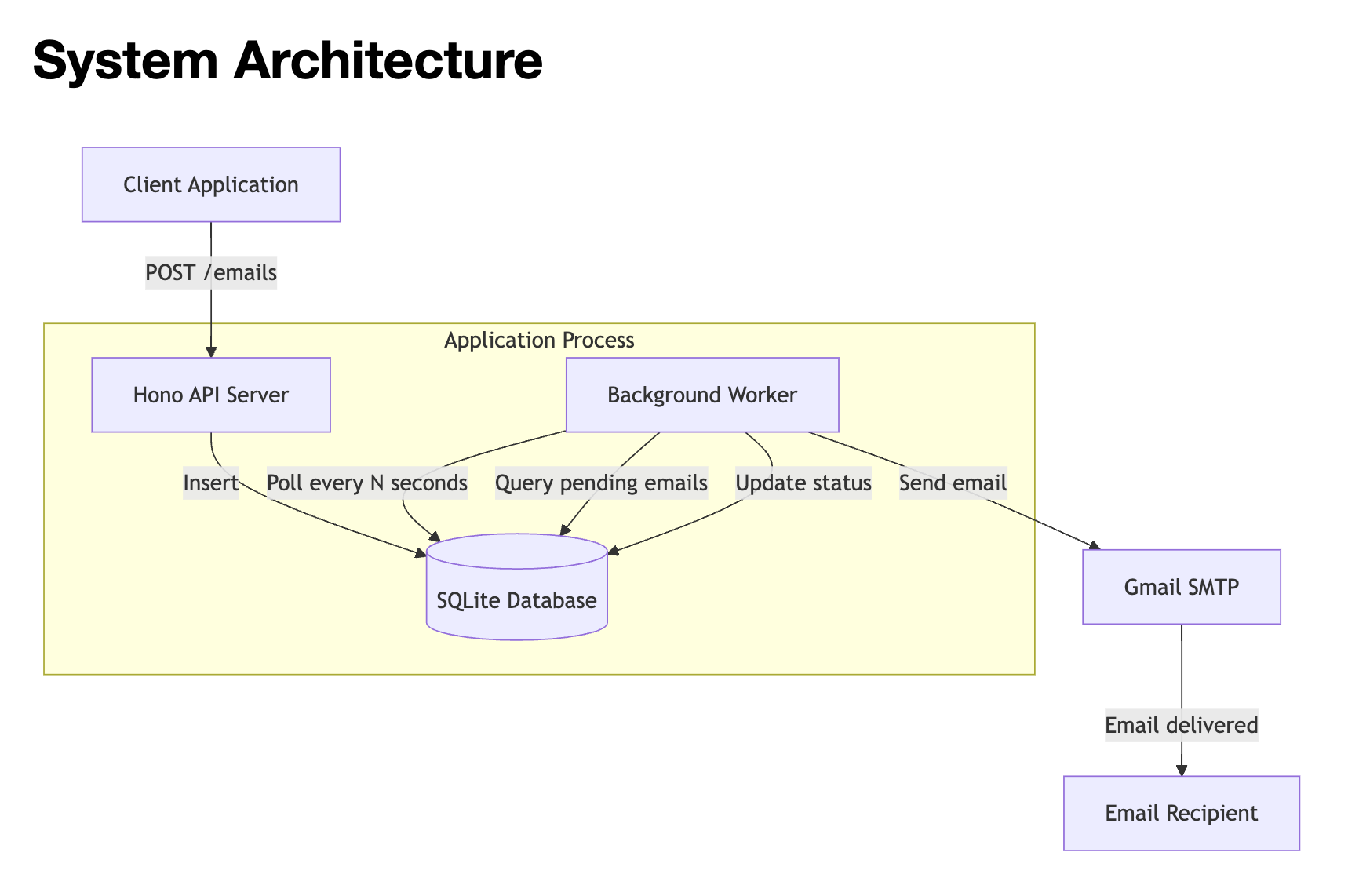
Results by agent
Cursor Plan Mode
We used the criteria above to score the output across 2 models for Cursor’s Plan Mode:

Cursor’s plans consistently showed:
Simpler database schemas
Standard retry logic without jitter
Single-file components (db.ts handles all database operations)
Kilo Code Architect Mode
We used the same criteria to score the output across 2 models for Cursor’s Plan Mode:

Kilo’s plans consistently included:
Database schemas with tracking fields (message IDs, attempt counts, next retry times)
Exponential backoff with jitter (GPT-5) or standard retries (Sonnet 4.5)
Nested module structure (email/smtp.ts, worker/scheduler.ts)
Health endpoints implemented (GPT-5) or planned for later (Sonnet 4.5)
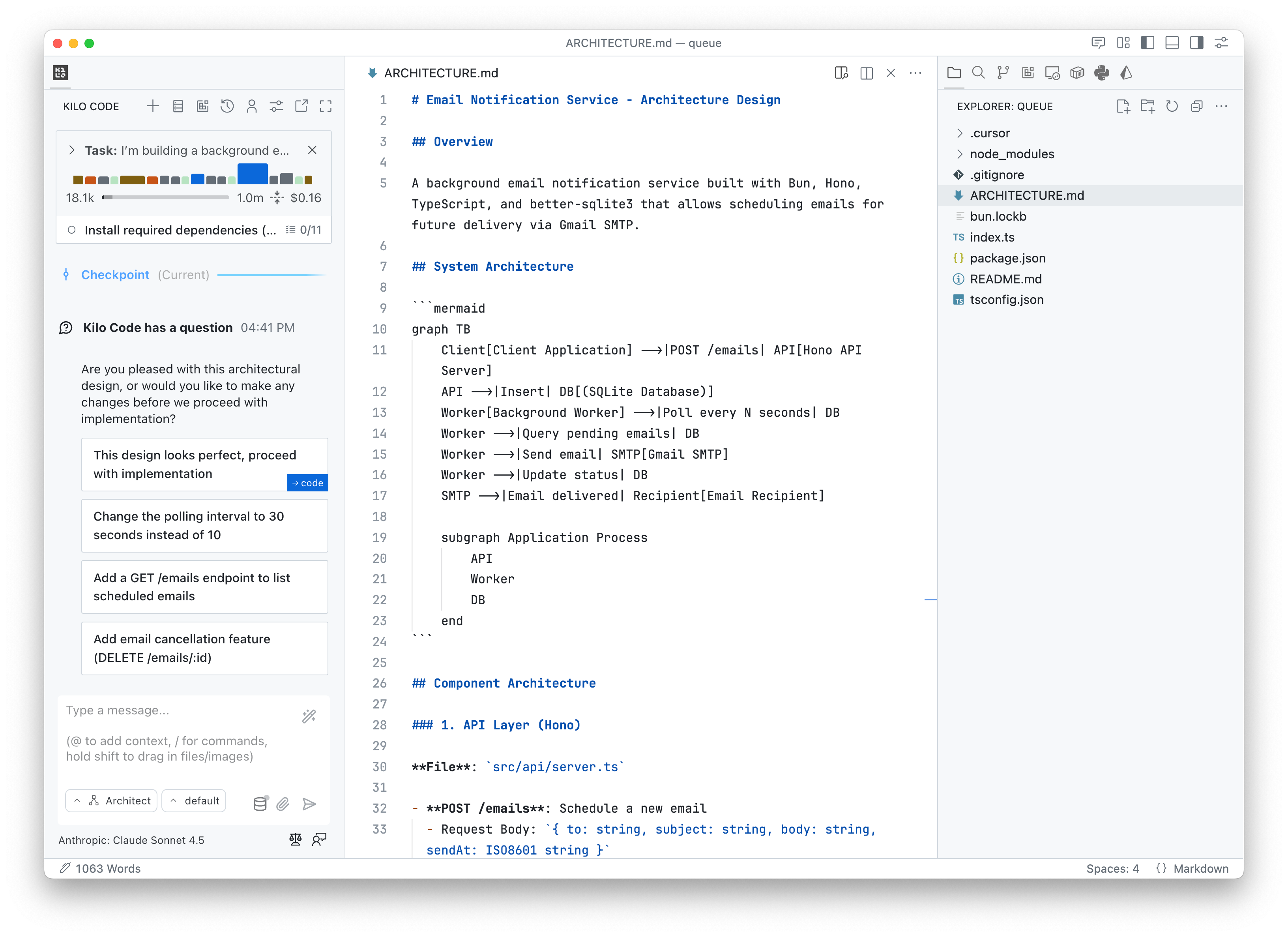
Where Kilo Code Architect Mode Scored Higher
The plans addressed more edge cases and production concerns. GPT-5 (9.5/10 reliability) in Kilo used transactional claiming to prevent race conditions, exponential backoff with jitter, and message ID tracking for idempotency. GPT-5 (8.0/10) in Cursor covered the essentials for reliable delivery in a simpler architecture.
Sonnet 4.5 in Kilo (9.5/10 decomposition) used nested module structure with separate api/, db/, services/, and worker/ folders. Sonnet 4.5 in Cursor maintained flatter structures with everything in root src/.


Where Cursor Plan Mode Scored Higher or Tied
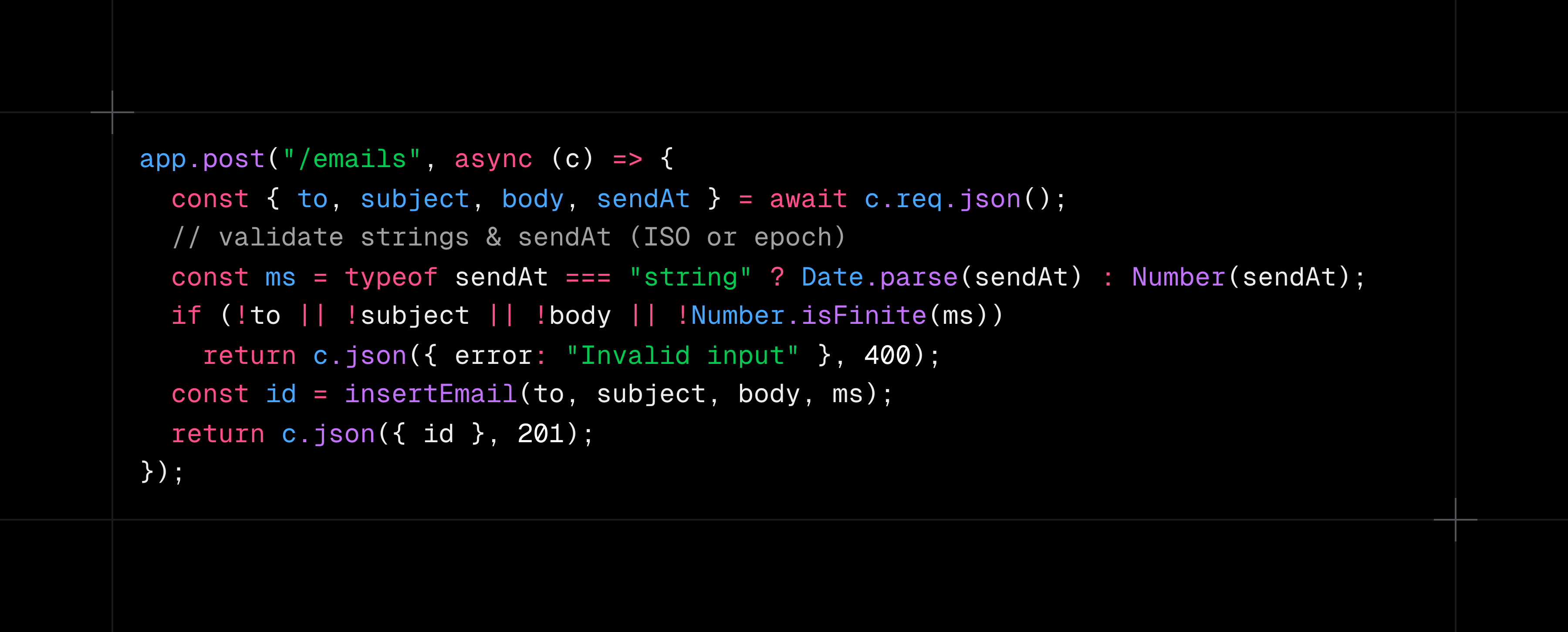
Cursor GPT-5 and Kilo GPT-5 tied at 9.0/10 for implementability. Cursor GPT-5 showed actual TypeScript code you could copy and run:
Kilo GPT-5 used file reference syntax:
[typescript.function schedulerLoop()](src/worker/scheduler.ts:1).Cursor Sonnet 4.5 (8.0/10 communication) had clear sections with explanations and implementation steps. Kilo Sonnet 4.5 achieved 10.0/10 with Mermaid diagrams, sections covering all aspects, and 10 future suggestions.
Note: Security Gap in GPT-5 Plans
Neither IDE mentioned rate limiting when using GPT-5. Cursor GPT-5 (5.0/10) had basic input validation but no authentication. Kilo GPT-5 (8.0/10) specified Zod validation schemas, character limits (512 chars for subject), and payload size limits (~200KB). Only Sonnet 4.5 plans addressed rate limiting.
Conclusion
When using Plan mode, Cursor averaged 7/10. When using Architect mode, Kilo averaged 8.7/10.
The agent you choose matters more than the model: GPT-5 averaged 7.9/10 across both agents, while Sonnet averaged 7.8/10, both nearly identical scores. Models mainly differed in how they explained things, not what they planned.
Cursor optimized for rapid development with straightforward architecture; best for iterating quickly based on real-world usage. Kilo included production features upfront; best when requirements are well-defined or when future refactoring would be costly.
Kilo Code is open source, so you can modify the Planning mode system prompt to prioritize either speed or production readiness.