
Claude Sonnet 4.5 Drops
The Coding Beast We've Been Waiting For?

Anthropic just dropped Claude Sonnet 4.5, and it’s already live in Kilo Code as anthropic/claude-sonnet-4.5. After running it through its paces, I’m convinced this is the model update that actually is significant for developers.
Here’s the headline: 82% on SWE-bench Verified. That’s not a typo. This thing solves real GitHub issues better than any model we’ve seen, including GPT-5-Codex…and even Opus 4.1.
The Numbers That Matter
Let me cut through the marketing and give you what actually counts:
SWE-bench Performance:
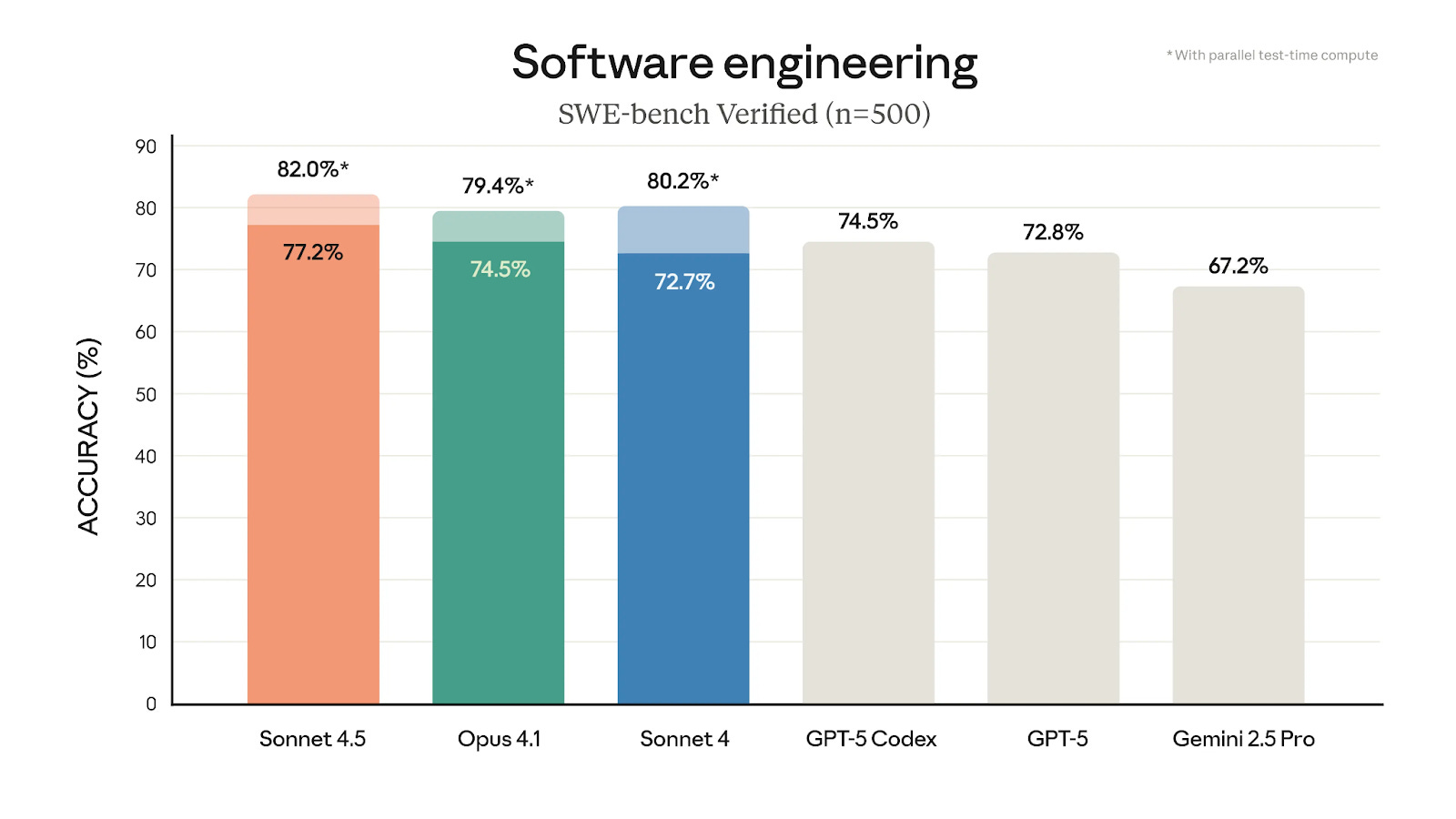
For context, SWE-bench tests whether models can fix actual bugs in real repositories. It’s the difference between writing a fizzbuzz function and debugging a race condition in production code.
What Makes This Different
Agent capabilities that actually work: The improved tool use isn’t just marginally better - it’s reliable enough to handle multi-step workflows without constant hand-holding. Better prompt injection resistance means your agents won’t get derailed by weird edge cases. This should mean that when you need it to modify files, call APIs, and update databases in sequence, it maintains coherence across the entire operation.
Automatic context management: The model can now automatically remove less relevant content while preserving conversation flow. This means agents can run autonomously for much longer without hitting context limits or losing track of what they’re doing. Anthropic has observed it maintaining focus for 30+ hours on complex tasks.
Real-World Testing
I threw Sonnet 4.5 at updating some of our internal tooling - the kind of gnarly refactoring that usually requires multiple rounds of back-and-forth.
The model:
Correctly identified the architecture patterns we were using
Maintained context across multiple file modifications
Wrote tests that actually passed
Handled edge cases I hadn’t even mentioned
2025: The Year of the…AI Desktop?
Anthropic is claiming 61.4% on OSWorld (up from 42.2% just four months ago). In practice, this should mean that the model can actually navigate UIs, fill out forms, and complete real tasks in a browser.
The Price Stays the Same
Here’s the kicker: same pricing as Sonnet 4 at $3 input / $15 output per million tokens.
For comparison
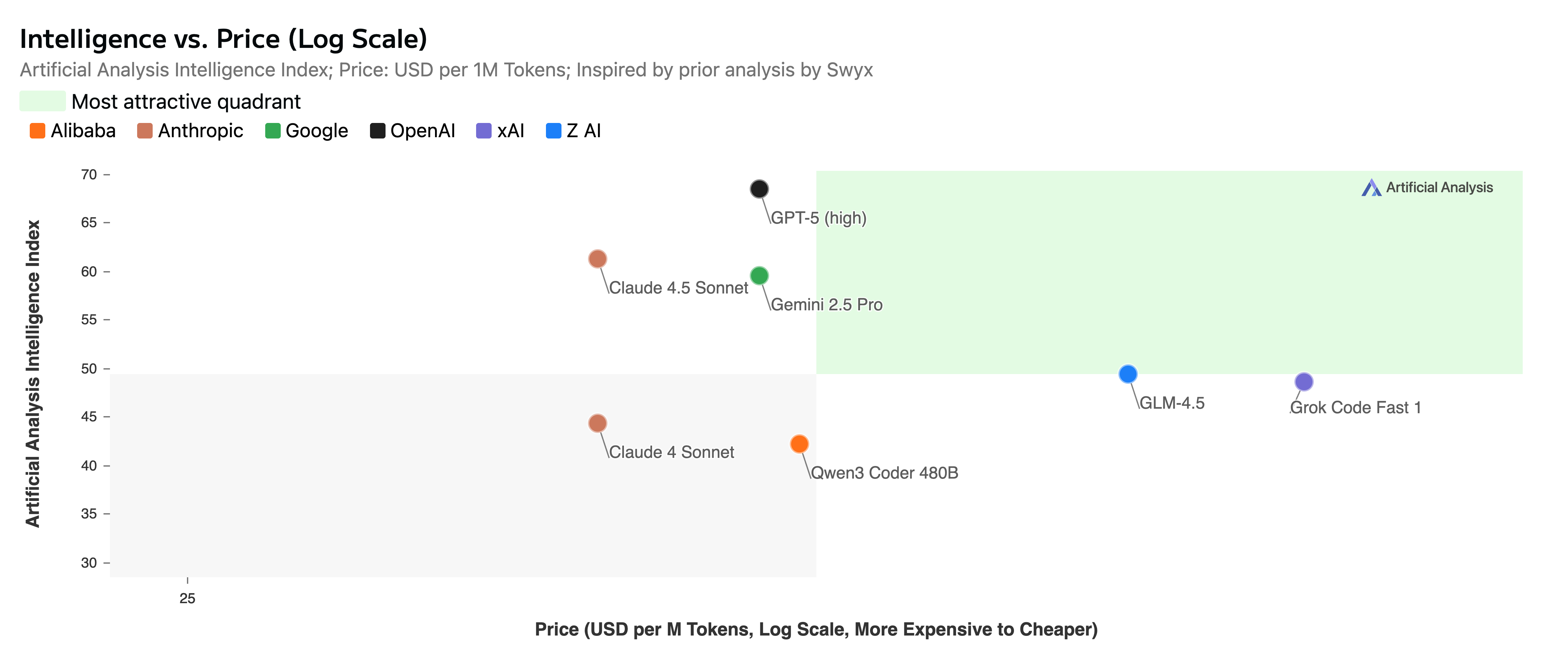
You’re getting frontier performance at mid-tier pricing. That changes the economics of AI coding pretty dramatically.
Using It in Kilo Code Right Now
It’s already live in Kilo Code. Just select anthropic/claude-sonnet-4.5 from your model dropdown, and you’re good to go.
The improved agent capabilities mean:
Better handling of large codebases
More reliable multi-file edits
Smarter context management across long conversations
Actually useful memory for multi-session projects
The Bottom Line
Claude Sonnet 4.5 isn’t revolutionary in the “AGI is here” sense. But for those of us actually building with these models, it’s the kind of practical upgrade that makes a difference.
Better code generation. Reliable tool use. Memory that persists. Automatic context management. All at the same price point.
Sometimes evolution beats revolution. And for developers who need to ship code today, that’s precisely what we want.
Ready to try it? Fire up Kilo Code and select anthropic/claude-sonnet-4.5 from your model list. With over 475,000 developers already using Kilo Code, you’re in good company.
I was quite excited to used it, but after burning 30$ in just a 10 minute workflow of analysis + refactor, I don't see a way in the short future of using this from a country where dollar is not the first currency.
There are definitely some issues with this new release. Sonnet 4.5 is even more token hungry than Sonnet 4 and thus even more expensive per task. While I'm sure prompt engineering from both Anthropic and Kilo will help, right now, Sonnet 4.5 is doing far worse at code refactoring and debugging than Sonnet 4 just a few days ago. I am still using Sonnet 4, but the performance has substantially degraded. I am going to stay away from both of these models for awhile until the performance problems are fixed.